 |
VOOZH | about |
|
VOOZH | about |
Root Mean Squared Error (RMSE) is the square root of the mean of the squared errors. It is a useful error metric for numerical predictions, primarily to compare prediction errors of different models or configurations for the same variable, as it is scale-dependent. RMSE measures how well a regression line fits the data.
Where:
Note: The difference between the actual values and the predicted values is known as residuals.
Here are some significance of RMSE.
Now we will discuss different method to compute RMSE in R Programming Language.
Let’s first compute the RMSE between two vectors (actual and predicted values) manually.
Output:
[1] 0.3464102
The above code calculates the RMSE between the actual and predicted values manually by following the RMSE formula.
The Metrics package offers a convenient rmse() function. First, install and load the package.
Output:
[1] 0.3464102
caret PackageThe caret package is a popular package for machine learning and model evaluation. It provides a similar RMSE() function.
Output:
[1] 0.3464102
In regression models, RMSE is used to evaluate the performance of the model. Let’s fit a linear regression model in R and compute the RMSE for the predicted values.
Output:
[1] 3.740297
This example fits a linear regression model predicting the miles per gallon (mpg) of cars based on horsepower (hp) and computes the RMSE to evaluate the model's prediction accuracy.
Interpreting RMSE involves understanding its relationship with the data.
However, the RMSE value should always be interpreted in the context of the data. For example, an RMSE of 10 might be considered good for a dataset where the target variable ranges between 100 and 500, but it could indicate poor performance if the target variable ranges between 0 and 20.
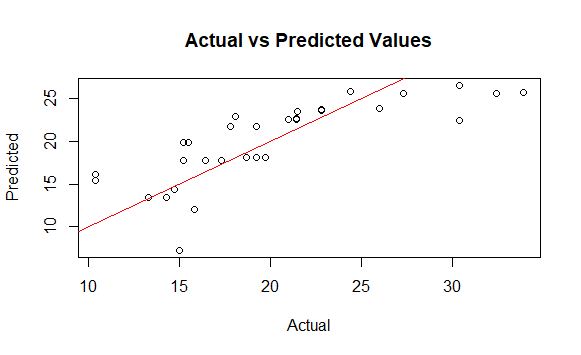
Visualizing the performance of our model can help in understanding where the model is underperforming. A scatter plot of actual vs. predicted values can provide insights into how well the model fits the data.
Output:
The closer the points are to the red line (where actual = predicted), the better the model's predictions.
{kind=link}
{kind=link}