 |
VOOZH | about |
|
VOOZH | about |
Machine Learning (ML) is a subset of Artificial Intelligence (AI) that enables computers to learn from data and improve their performance over time without being explicitly programmed. The choice of ML algorithms depends on the type of data and the task at hand which can be broadly divided into Supervised and Unsupervised Learning.
In the context of Machine Learning data can be divided into two types:
The distinction between these two types of data forms the foundation for Supervised and Unsupervised Learning.
Supervised learning involves training a model on labeled data where both the input data and the correct output (label) are provided. The goal is to predict the output for new or unseen data.
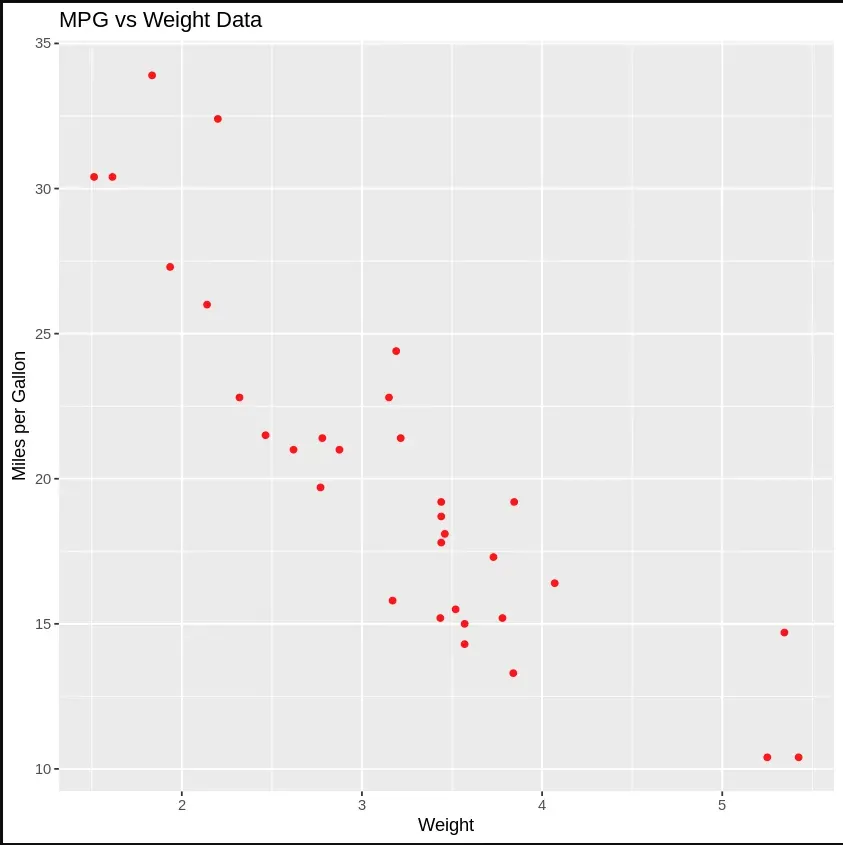
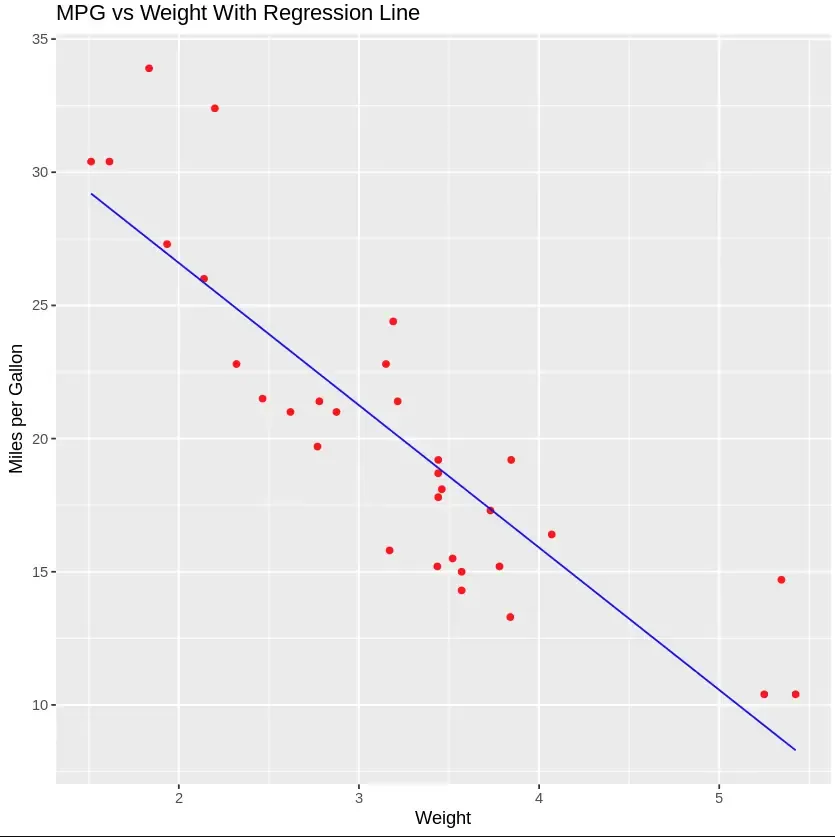
Linear Regression is a supervised learning algorithm used for predicting continuous values. We will use an example of implementing Simple Linear Regression in R.
Output:
Unsupervised learning deals with datasets that are not labeled. The algorithm tries to identify hidden patterns or groupings in the data. There is no supervision, meaning the model does not know the "right" answers in advance.
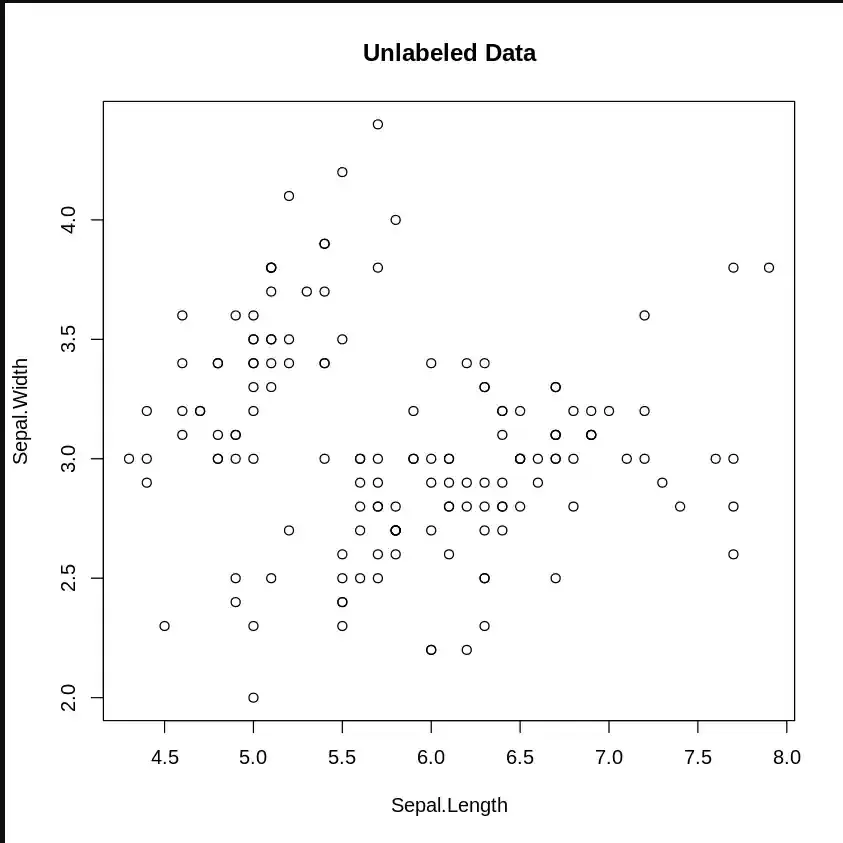
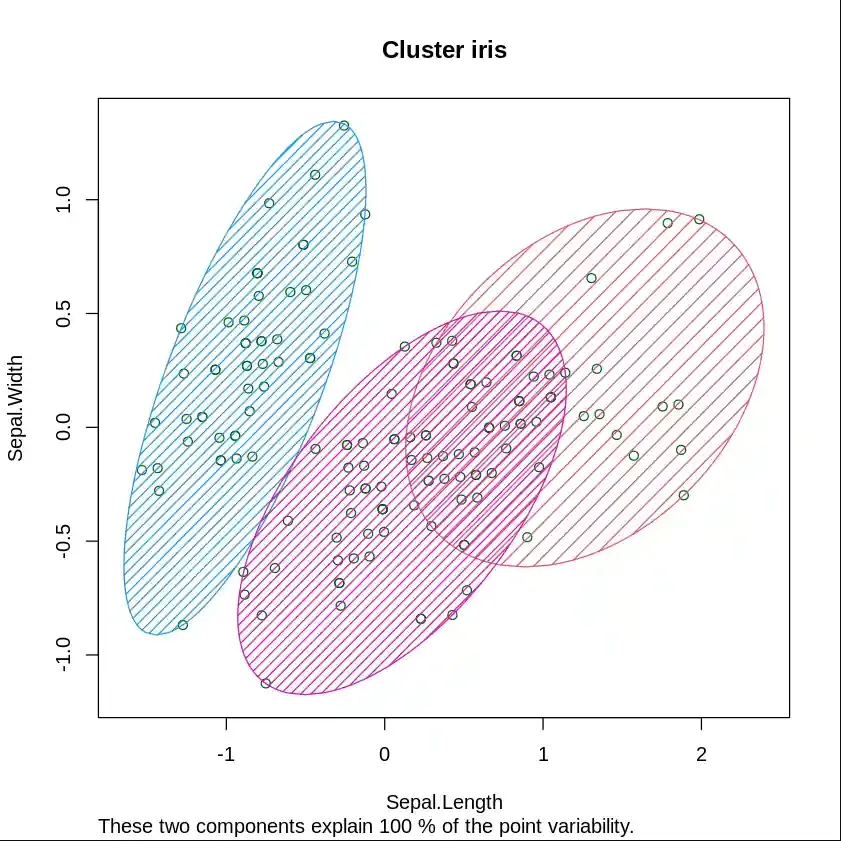
K-Means Clustering is an unsupervised algorithm that divides data into clusters based on similarity. We will use an example of implementing K-Means Clustering in R.
Output:
In this article, we explored Supervised and Unsupervised Learning in R programming and understood how to decide which type of machine learning algorithm to use.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}