 |
VOOZH | about |
|
VOOZH | about |
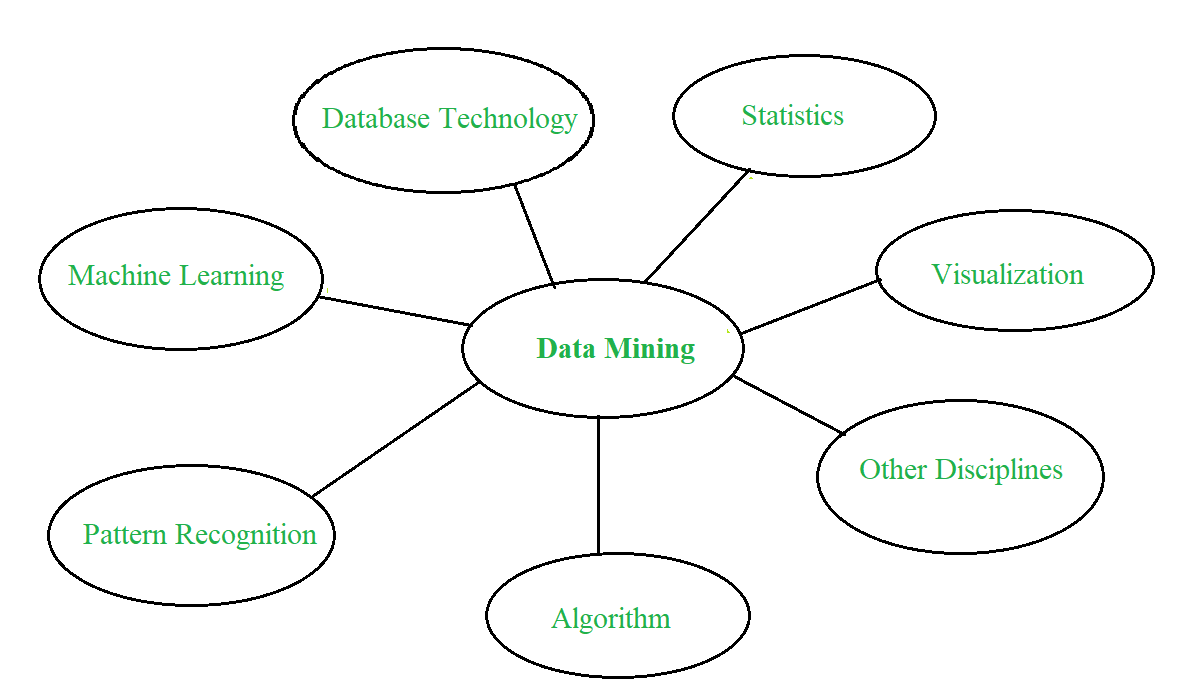
Data mining is the process of extracting useful and previously unknown patterns from large datasets. It combines methods from artificial intelligence, machine learning, statistics, and database systems to discover hidden insights that can support better decision making. Although the term suggests just extracting data, the real focus is on uncovering valuable knowledge making "knowledge mining" a more accurate name.
The main goal is to transform raw data into meaningful and understandable information that can be used by organizations to gain insights, improve strategies, and make informed decisions.
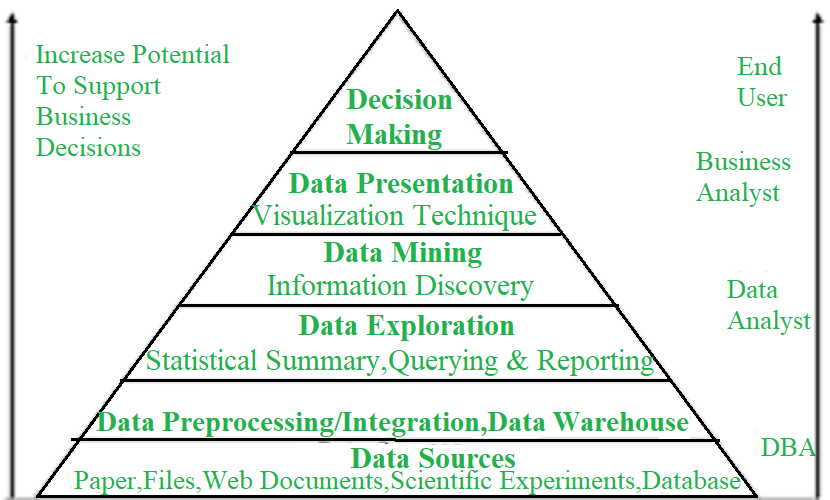
Data Mining is a process of discovering various models, summaries, and derived values from a given collection of data.
Let's discuss each layer of data processing in detail:
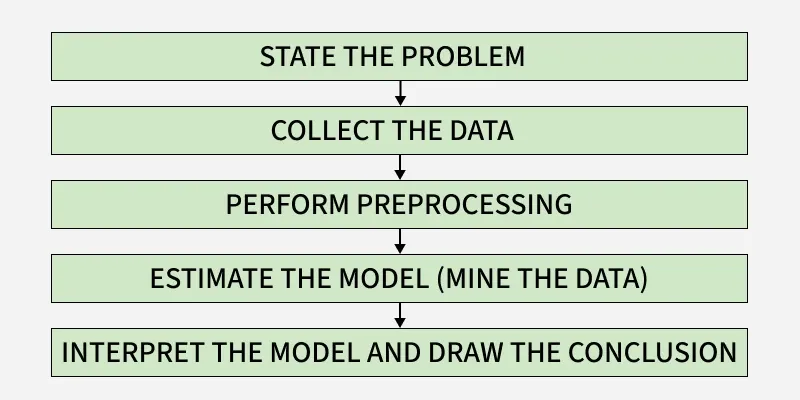
In this step, the modeler defines key variables and forms initial hypotheses about their relationships. It requires close collaboration between domain experts and data mining professionals. This teamwork starts early and continues throughout the entire data mining process to ensure meaningful results.
This step focuses on how data is collected. There are two main approaches
It's important to understand how data was collected, as this affects its distribution and the accuracy of the model. Also, the data used for training and testing must come from the same distribution-otherwise, the model may not work well in real-world applications.
In the observational setting, data is usually "collected" from prevailing databases, data warehouses, and data marts. Data preprocessing usually includes a minimum of two common tasks :
(i) Outlier Detection: Outliers are unusual data values that are not according to most observations. There are two strategies for handling outliers:
(ii) Scaling, encoding, and selecting features: Data preprocessing involves steps like scaling and encoding variables. For example, if one feature ranges from 0–1 and another from 100–1000, they can unfairly influence results. Scaling adjusts them to the same range so all features contribute equally. Encoding methods also help reduce data size by transforming features into a smaller set of meaningful variables for better modeling.
Apply and test different data mining techniques. It often requires trying multiple models and comparing results to choose the best fit.
The final model should support decision-making and be interpretable. Simpler models are easier to explain but may lack accuracy, while complex models need special methods for interpretation.
Classification of Data Mining Systems :
{kind=link}
{kind=link}
{kind=link}
{kind=link}