A B+ Tree is an advanced data structure used in database systems and file systems to maintain sorted data for fast retrieval, especially from disk. It is an extended version of the B Tree, where all actual data is stored only in the leaf nodes, while internal nodes contain only keys for navigation.
Components of B+ Tree
Leaf nodes store all the key values and pointers to the actual data.
Internal nodes store only the keys that guide searches.
All leaf nodes are linked together, supporting efficient sequential and range queries.
This structure makes the B+ Tree balanced, disk-efficient, and ideal for database indexing.
Features of B+ Trees
Balanced: Auto-adjusts when data is added or removed, keeping search time efficient.
Multi-level: Has a root, internal nodes, and leaf nodes (which store the data).
Ordered: Maintains sorted keys, making range queries easy.
High Fan-out: Each node has many children, keeping the tree short and fast.
Cache-friendly: Works well with memory caches for better speed.
Disk-efficient: Ideal for disk storage due to fast data access.
How B+ Trees Work
The Structure of the Internal Nodes of a B+ Tree of Order 'a' is as Follows
Each internal node is of the form: <P1, K1, P2, K2, ....., Pc-1, Kc-1, Pc> where c <= a and each Pi is a tree pointer (i.e points to another node of the tree) and, each Ki is a key-value (see diagram-I for reference).
Every internal node has : K1 < K2 < .... < Kc-1
For each search field value 'X' in the sub-tree pointed at by Pi, the following condition holds: Ki-1 < X <= Ki, for 1 < I < c and, Ki-1 < X, for i = c (See diagram I for reference)
Each internal node has at most 'a' tree pointers.
The root node has, at least two tree pointers, while the other internal nodes have at least tree pointers each.
If an internal node has 'c' pointers, c <= a, then it has 'c - 1' key values.
The Structure of the Leaf Nodes of a B+ Tree of Order 'b' is as Follows
Each leaf node is of the form: <<K1, D1>, <K2, D2>, ....., <Kc-1, Dc-1>, Pnext> where c <= b and each Di is a data pointer (i.e points to actual record in the disk whose key value is Ki or to a disk file block containing that record) and, each Ki is a key value and, Pnext points to next leaf node in the B+ tree (see diagram II for reference).
Every leaf node has : K1 < K2 < .... < Kc-1, c <= b
In the below diagram, we can see that using the Pnext pointer it is viable to traverse all the leaf nodes, just like a linked list, thereby achieving ordered access to the records stored in the disk.
Navigate through internal nodes based on key comparisons
Reach the appropriate leaf node
If the key exists, return the data; otherwise, report "record not found"
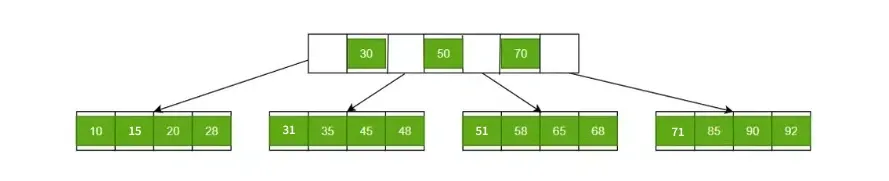
Example: In the image below, in order to search for 58, traverse the root → internal node → reach the correct leaf node that contains 58 (if it exists).
Separate leaf nodes for data storage and internal nodes for indexing
Nodes store both keys and data values
Leaf Nodes
Leaf nodes form a linked list for efficient range-based queries
Leaf nodes do not form a linked list
Order
Higher order (more keys)
Lower order (fewer keys)
Key Duplication
Typically allows key duplication in leaf nodes
Usually does not allow key duplication
Disk Access
Better disk access due to sequential reads in a linked list structure
More disk I/O due to non-sequential reads in internal nodes
Applications
Database systems, file systems, where range queries are common
In-memory data structures, databases, general-purpose use
Performance
Better performance for range queries and bulk data retrieval
Balanced performance for search, insert, and delete operations
Memory Usage
Requires more memory for internal nodes
Requires less memory as keys and values are stored in the same node
Advantages
A B+ tree with 'l' levels can store more entries in its internal nodes compared to a B-tree having the same 'l' levels. This accentuates the significant improvement made to the search time for any given key. Having lesser levels and the presence of Pnext pointers imply that the B+ trees is very quick and efficient in accessing records from disks.
Data stored in a B+ tree can be accessed both sequentially and directly.
It takes an equal number of disk accesses to fetch records.
B+trees have redundant search keys, and storing search keys repeatedly is not possible.
Disadvantages
Slower exact match: Data is always in leaf nodes, increasing search path.
More disk access: Requires reaching the leaf even for a single record.
Complex updates: Insertion and deletion are more complex.
Extra space: Leaf node links need additional pointers.

{kind=link}
-768.webp){kind=link}
-768.webp){kind=link}
-768.webp){kind=link}
{kind=link}