 |
VOOZH | about |
|
VOOZH | about |
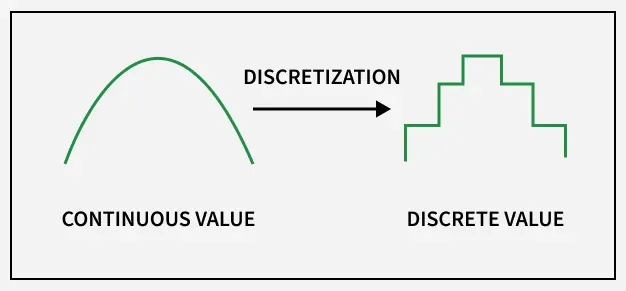
Discretization is the process of converting continuous data or numerical values into discrete categories or bins. This technique is often used in data analysis and machine learning to simplify complex data and make it easier to analyze and work with. Instead of dealing with exact values, discretization groups the data into ranges and helps algorithms perform better especially in classification tasks.
There are several types of discretization techniques used in data analysis to convert continuous data into discrete categories nut mainly binning is used. Here are some of the common methods:
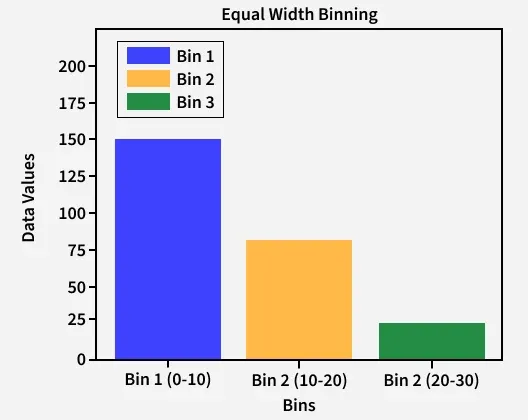
This technique divides the entire range of data into equal-sized intervals. Each bin has an equal width, determined by dividing the range of the data into intervals.
Formula:
For example, if you have data from 1 to 100, you can divide it into 5 intervals: 1-20, 21-40, 41-60, 61-80, and 81-100.
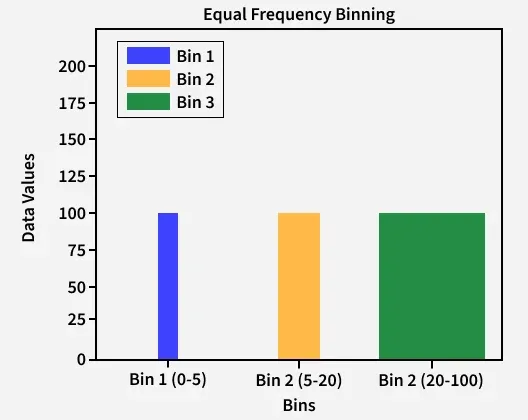
This method divides the data so that each interval has the same number of data points. For example, if you have 100 data points, you might divide them into 5 intervals, each containing 20 data points.
K-means Clustering uses clustering algorithms to group data into clusters based on similarity. The data points in each cluster are treated as a single category.
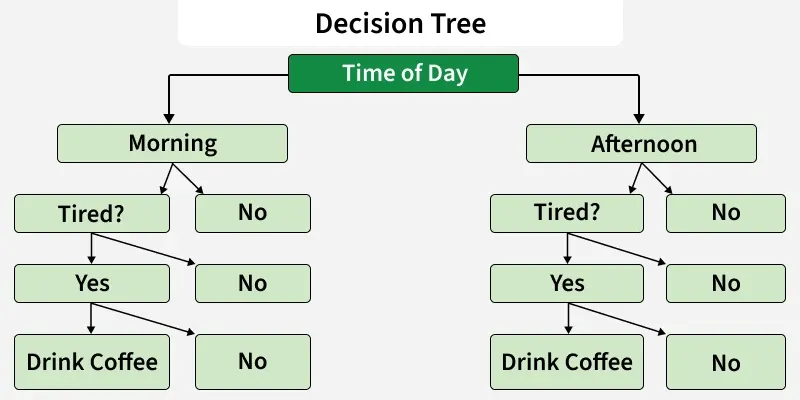
This method uses decision trees to split the data based on feature values, turning continuous variables into discrete categories that help in prediction. There are several decision tree algorithms that are designed for specific tasks such as classification, regression, or handling imbalanced data.
Domains such as healthcare, finance, or demographics may require manually defined bins.
Example: Categorizing age into ranges like 0–18, 19–40, and 41+.
This method relies on domain knowledge and allows for highly interpretable categories.
| Aspect | Discretization | Binning |
|---|---|---|
| Definition | Any method that converts continuous data into categories | A specific discretization technique that groups data into intervals |
| Flexibility | High (tree-based, clustering, custom rules) | Moderate (equal width, equal frequency, manual bins) |
| Common Use | Machine learning preprocessing | Data simplification & noise reduction |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}