A lossless decomposition is a process of decomposing a relation schema into multiple relations in such a way that it preserves the information contained in the original relation.
Joining the decomposed tables gives back the original table.
After decomposition, the union of attributes of X₁ and X₂ must be equal to the attributes of the original relation X.
X₁ and X₂ must have at least one common attribute (intersection should not be NULL).
The common attribute must be a super key in at least one of the decomposed relations (X₁ or X₂) and also should have unique values to ensure a lossless join.
To Check for Lossless Decomposition
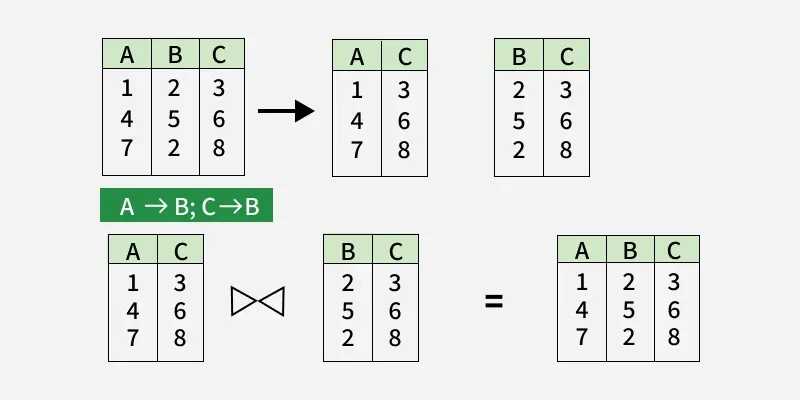
For lossless decomposition, we have to ensure three major things. Suppose any relation R (A, B, C, D) is decomposed into relations R1 (A, B, C) and R2 (C, D), then check for :
Union of attributes set of R1 & R2 should be equal to the attribute set of R, i.e., R1 ∪ R2 = R.
Intersection of attributes set of R1 & R2 should not be empty set, i.e., R1 ∩ R2
Attribute closure of intersection of attributes set of R1 & R2is either superset of R1 or R2, i.e., (R1 ∩ R2)+ ⊇ R1 or (R1 ∩ R2)+ ⊇ R2
Not all decompositions into 1NF, 2NF, 3NF, or BCNF are guaranteed to be lossless.
Closure of Dept_Id (with proper FDs) should cover either R1 or R2 to ensure lossless join:
(R1 ∩ R2 -> R1) or (R1 ∩ R2 -> R2)
Armstrong’s Axioms and Lossless Decomposition
Armstrong’s Axioms are a set of simple rules used to derive all possible functional dependencies (FDs) from a given set. These dependencies help in analyzing whether a database decomposition is lossless. Armstrong’s Axioms themselves do not directly prove that a decomposition is lossless; instead, they are used to find attribute closures and check dependency conditions, which then help in determining losslessness.
The three core axioms are:
Reflexivity: If Y ⊆ X, then X → Y
Augmentation: If X → Y, then XZ → YZ for any Z
Transitivity: If X → Y and Y → Z, then X → Z
Using these rules, you can determine the closure of attribute sets, which helps verify if (R1 ∩ R2)+ covers R1 or R2.
Note: Algorithms for performing lossless decomposition in DBMS are:
Reduced Data Redundancy: Helps remove repetitive data and optimize storage.
Maintenance and Updates: Smaller tables are easier to update and manage.
Improved Data Integrity: Ensures that only relevant attributes stay together.
Improved Flexibility: Easier to modify individual relations without affecting others.
Question Asked in GATE
Q.1: Let R (A, B, C, D) be a relational schema with the following functional dependencies:
A -> B, B -> C, C -> D and D -> B. The decomposition of R into (A, B), (B, C), (B, D)
(A) gives a lossless join and is dependency preserving (B) gives a lossless join, but is not dependency preserving (C) does not give a lossless join, but is dependency preserving (D) does not give a lossless join and is not dependency preserving

{kind=link}
{kind=link}