Amazon Web Services (AWS) is a subsidiary of Amazon offering cloud computing services and APIs to businesses, organizations, and governments. It provides essential infrastructure, tools, and computing resources on a pay-as-you-go basis. AWS Data Pipeline is a service that allows users to easily transfer and manage data across AWS services (e.g., S3, EMR, DynamoDB, RDS) and external sites. It supports complex data processing tasks, error handling, and data transfer, enabling reliable, scalable data workflows.
Workflow of AWS Data pipeline
To access the AWS data pipeline first we have to create an AWS account on the website.
From the AWS webpage, we have to go to the data pipeline and then we have to select the ‘Create New Pipeline’.
Then we have to add personal information whatever it has asked for. Here we have to select ‘Incremental copy from MYSQL RDS to Redshift.
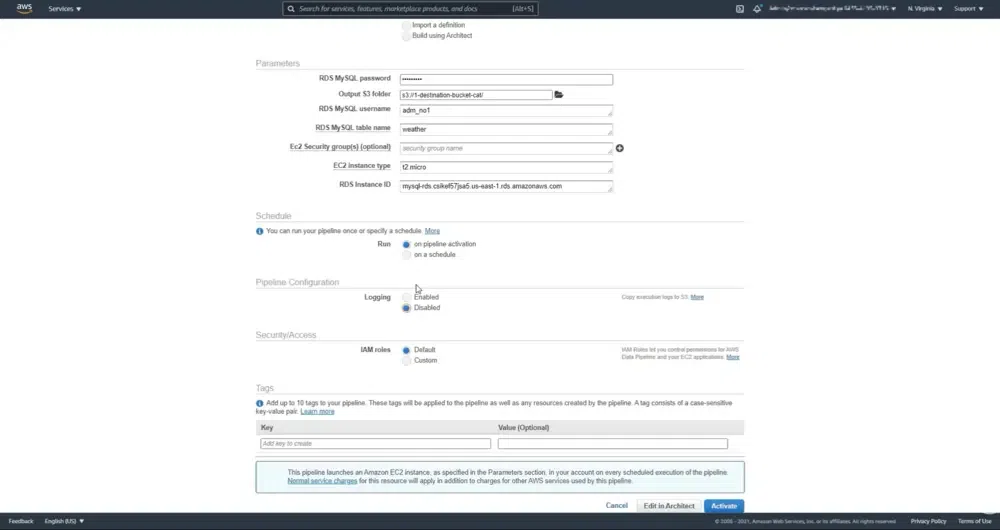
Then we have to write all the data which are asked in the parameters for RDS MYSQL details.
Then arrange the Redshift connection framework.
We have to schedule the application to run or we can access it for one time run through activation.
After that, we have to approve the logging form. This is very useful for troubleshooting projects.
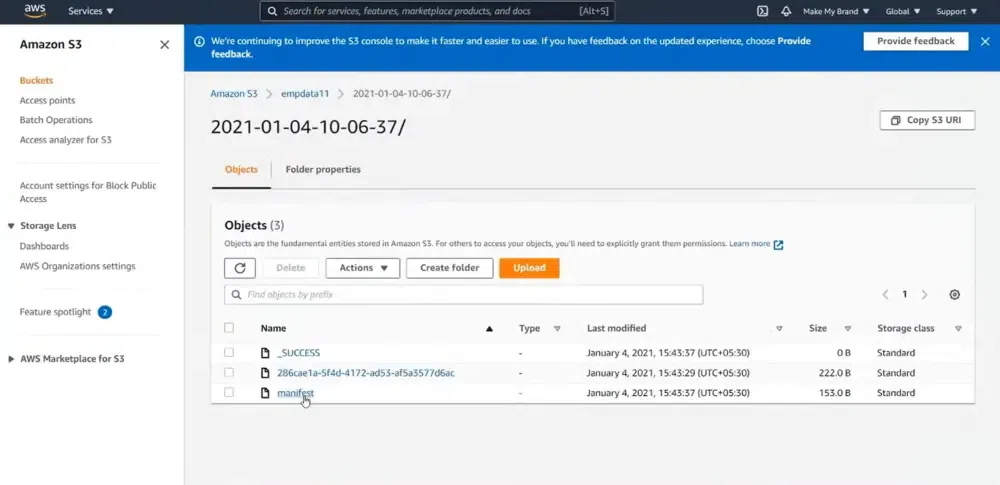
The last step is just to activate it and we are ready to use it.
Components of AWS Data Pipeline
The AWS Data Pipeline Definition specifies on how business teams should communicate with the Data Pipeline. It contains different information:
Data Nodes: These specify the name, position, and format of the data sources similar to Amazon S3, Dynamo DB, etc.
Conditioning: Conditioning is the conduct that performs the SQL Queries on the databases, and transforms the data from one data source to another data source.
Schedules: Scheduling is performed on the Conditioning.
Preconditions: Preconditions must be satisfied before cataloging the conditioning. For illustration, if you want to move the data from Amazon S3, also precondition is to check whether the data is available in Amazon S3 or not.
Facility: You have Resources similar to Amazon EC2 or EMR cluster.
Conduct: It updates the status of your channel similar to transferring a dispatch to you or sparking an alarm.
Pipeline factors: We've formerly bandied about the pipeline factors. It is principally how you communicate your Data Pipeline to the AWS services.
Cases: When all the pipeline factors are collected in a channel(pipeline), also it creates a practicable case that contains the information of a specific task.
Attempts: Data Pipeline allows, retrying the operations which are failed. These are nothing but Attempts.
Task Runner: Task Runner is an operation that does the tasks from the Data Pipeline and performs the tasks.
Accessing of AWS Data Pipeline involves several key steps those discussed as follows. Here we discussed an effective and streamlined workflow of data processing.
Step 1: Login to AWS Console
Firstly, login in to your AWS Console and login with your credentials such as username and password.
Define the configuration of the pipeline by specifying the data sources, activities, schedules and resources that are needed and define them as per requirements.
Configure the individual components of the pipeline by specifying the details such as input or output locations, resource requirements and processing logic.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}