 |
VOOZH | about |
|
VOOZH | about |
Parameter-Efficient Fine-Tuning (PEFT) is a technique that fine-tunes large pretrained language models (LLMs) for specific tasks by updating only a small subset of their parameters while keeping most of the model unchanged. This approach typically reduces computational costs and training time of LLMs for specialised tasks without retraining the entire model.
Traditional fine-tuning updates a pre-trained model to perform a specific task, but it becomes inefficient as model size grows. Modern LLMs contain billions of parameters making full fine-tuning costly and resource-intensive.
A large language model is first taken that has already learned general language patterns from vast amounts of training data. This pretrained knowledge serves as a strong foundation, allowing it to be efficiently fine-tuned for specific tasks.
In PEFT, the original pre-trained model is not updated during training. Instead, it's weights are kept fixed and only a small set of additional parameters are trained for the new task.
Instead of modifying the entire model, PEFT introduces small, task-specific components that can be trained while the main model stays frozen. These components capture the changes needed for the new task.
In PEFT, training is focused only on the newly added or selected parameters, while the main model remains completely unchanged. This makes the fine-tuning process much more efficient and targeted.
After fine-tuning, only the small task-specific components are stored and used, while the main pre-trained model remains the same. This makes deployment highly efficient and scalable.
PEFT is not a single technique but a collection of methods designed to efficiently fine-tune large language models. Each method takes a different approach to updating a small subset of parameters and the choice depends on factors like the task, available resources and required performance.
Adapter modules are small neural network layers inserted between the layers of a pre-trained model. During fine-tuning, only these adapters are trained while the original model weights remain frozen, enabling efficient and modular learning.
Hugging Face AdapterHub provides a collection of pre-trained adapters that can be plugged into models for tasks like text classification, translation and question answering without modifying the original model.
LoRA reduces the number of trainable parameters by representing weight updates as low-rank matrices. Instead of modifying the full weight matrix, it learns small, efficient updates that approximate the required changes for fine-tuning.
LoRA has been widely used with large models like GPT-3 and T5, where it enables efficient fine-tuning for tasks such as text generation and summarization without updating billions of parameters.
DoRA extends LoRA by introducing a weight-decomposition strategy, where model weights are separated into a scaling component and a low-rank update. This allows more precise control over parameter updates while keeping the process efficient.
DoRA is useful in scenarios like cross-domain adaptation or multilingual tasks, where models need to efficiently adapt to new data distributions while maintaining strong performance.
Prefix tuning is a PEFT technique where a small set of learnable prefix vectors is added to the model at each layer. These prefixes guide the model’s behavior for a specific task without modifying the original model parameters.
Prefix tuning is commonly used in text generation tasks, where the learned prefixes can control the style, tone, or content of the generated output without retraining the full model.
Prompt tuning is a PEFT technique that learns a set of soft (continuous) prompt vectors added to the input sequence. Unlike other methods, it operates only at the input level, without modifying the internal layers of the model.
Prompt tuning is effective in few-shot learning scenarios, where limited labeled data is available, allowing quick adaptation of the model to tasks like classification or text generation.
BitFit fine-tunes only the bias terms of a neural network while keeping all other parameters frozen. Despite updating very few parameters, it can still achieve strong performance on many NLP tasks.
BitFit can be used for tasks like sentiment analysis or text classification, where adjusting only bias terms is often enough to adapt the model without full fine-tuning.
(IA)3 adjusts a model’s behavior by scaling its internal activations instead of adding new layers or heavily modifying weights. It introduces small, learnable parameters that control how information flows through the network.
(IA)3 is effective in tasks like text classification, where subtle adjustments in internal representations can significantly improve performance without full fine-tuning.
Here we implement Parameter-Efficient Fine-Tuning (PEFT) using LoRA as an example technique on the IMDb dataset. This demonstrates how PEFT methods can efficiently adapt large models while training only a small subset of parameters.
Install required libraries Transformers, Datasets, Peft, Accelerate and Scikit Learn to set up the fine-tuning environment.
We use BERT-base-uncased as our pre-trained model which already has strong language understanding. The IMDb dataset contains 50k movie reviews labeled as positive or negative. This combination makes it a good benchmark to show PEFT for sentiment analysis.
Before training, we tokenize the reviews so that BERT can process them. Each review is truncated or padded to a maximum length of 128 tokens for consistency. Finally we rename label to labels and set the dataset format to PyTorch tensors.
Instead of updating all BERT weights, we configure LoRA (Low-Rank Adaptation) to inject small trainable matrices inside the attention layers (query, value). This reduces the number of trainable parameters while still adapting the model effectively. The dropout helps avoid overfitting during fine-tuning.
We define training arguments using Hugging Face’s Trainer.
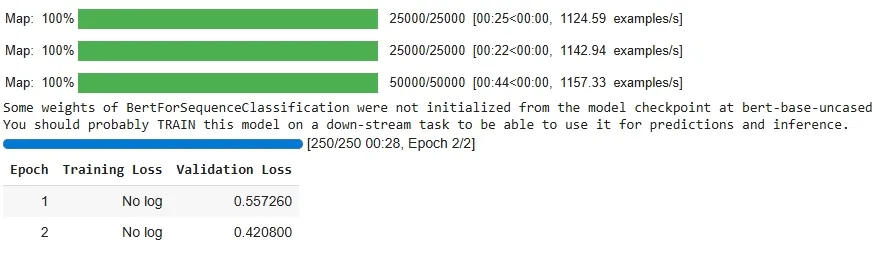
Output:
Once trained, we can test our model on new sentences. We load the fine-tuned LoRA adapter and run a few sample reviews through a sentiment pipeline. The output gives us the predicted label (POSITIVE or NEGATIVE) along with confidence scores between 0 and 1.
Output:
The results are decent but not highly accurate yet, mainly because we trained for only 2 epochs on a small subset of the IMDb dataset (2000 samples). With longer training, more data, hyperparameter tuning or larger LoRA ranks, the model’s performance would improve significantly.
You can download source code from here.
When we compare full fine-tuning with parameter-efficient fine-tuning (PEFT), the differences become clear:
| Attribute | Full Fine-Tuning | PEFT (Parameter-Efficient Fine-Tuning) |
|---|---|---|
| Parameters Updated | Updates every parameter of the model (billions of weights). | Updates only a small subset or adds small modules; base model stays frozen. |
| Compute Requirement | Needs very high compute (multi-GPU / TPU). | Can run on a single GPU or modest hardware. |
| Storage Requirement | Stores a full model for each task; heavy storage usage. | Stores only small adapter weights; base model reused. |
| Performance | Strong results but expensive and less scalable. | Almost same performance but much cheaper and scalable. |
| Practicality | Difficult in low-resource setups; fits large labs. | Practical for edge devices, startups, universities, research groups. |
{kind=link}
{kind=link}
{kind=link}