 |
VOOZH | about |
|
VOOZH | about |
Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning technique used to adapt large pre-trained models for specific tasks with minimal computational and memory overhead. As models grow larger, full fine-tuning becomes expensive. LoRA addresses this by reducing the number of trainable parameters, making the process faster and more efficient.
Instead of updating the entire model, it introduces low-rank matrices into the model's layers. This allows us to adapt the model for specific tasks without changing the whole structure, maintaining high performance while reducing resource usage.
This approach helps us adapt large models to new tasks without changing the entire structure making it more efficient.
LoRA modifies the traditional fine-tuning process by introducing low-rank matrices into specific layers of a neural network allowing the model to adapt to new tasks without changing the entire model. Let's see how LoRA works:
Instead of updating the entire weight matrix during fine-tuning, it approximates it using two smaller low-rank matrices A and B. The adapted weight matrix (W') is calculated as:
Here W is the original weight matrix and A and B are the low-rank matrices. This decomposition allows the model to make task-specific adjustments without the need to retrain the entire model, drastically reducing the computational load.
During the fine-tuning process, only the low-rank matrices A and B are updated while the original model weights W remain frozen. This minimizes the number of parameters that need to be adjusted making fine-tuning faster and more memory-efficient compared to traditional methods where all model weights are updated.
After fine-tuning, the adapted weight matrix W′ is used for inference. This helps the model to make predictions for specific tasks, fine-tuned with minimal computational resources. Since only the low-rank matrices are updated, it maintains efficiency even during inference.
By using LoRA, we can adapt large pre-trained models to new tasks quickly and efficiently without the computational burden of full model fine-tuning.
Here we will see a practical implementation of LoRA on the Emotion Dataset. Instead of updating the entire BERT model, we fine-tune only small LoRA modules, saving time and resources while still achieving good performance in classifying emotions such as joy, sadness, anger, love, fear and surprise.
We use Hugging Face’s transformers, datasets, peft, accelerate and evaluate libraries for model training, LoRA fine-tuning and evaluation.
!pip install transformers datasets peft accelerate evaluate
We will be importing BERT, tokenizer, LoRA config, dataset loader, training utilities and PyTorch for this implementation.
We load the Emotion dataset(dair-ai/emotion). For quick implementation, we use only 3,000 training samples and smaller validation/test subsets.
Output:
Before training, we tokenize the text so BERT can process it. Each input is padded or truncated to 128 tokens for uniformity. We also rename label to labels and set the dataset format to PyTorch tensors. Then we load BERT-base-uncased for sequence classification with 6 output labels.
Output:
Instead of training all of BERT’s 110M+ parameters, LoRA injects small trainable matrices into the attention layers (query, value). This makes fine-tuning efficient without sacrificing much performance.
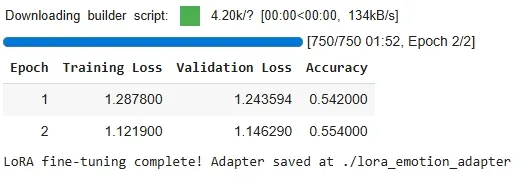
We fine-tune only the LoRA layers using Hugging Face’s Trainer API.
Output:
The accuracy here is not very high (~54%) because we trained only for 2 epochs on a small subset of the dataset. This setup is mainly for demonstration and understanding. For better performance, we can train for more epochs and use the full dataset.
Now let’s test our fine-tuned model on some custom sentences. This helps us confirm that the LoRA adapter works as intended.
Output:
You can download source code from here.
Different fine-tuning techniques have their strengths and weaknesses. Let's see a comparison of LoRA with some of the common techniques used for fine-tuning large models:
| Technique | Parameter Efficiency | Computation Cost | Model Preservation |
|---|---|---|---|
| Full Fine-Tuning | High | High | No |
| Adapter Layers | Moderate | Moderate | Yes |
| LoRA | High | Low | Yes |
| Prefix Tuning | High | Moderate | Yes |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}