 |
VOOZH | about |
|
VOOZH | about |
Scikit-Learn is one of the most popular libraries of Python for machine learning. This library comes equipped with various inbuilt datasets perfect for practising and experimenting with different algorithms. These datasets cover a range of applications, from simple classification tasks to more complex regression problems.
In this article, we will learn about some of the Top Inbuilt data sets in the Skcikit-Learn Library.
Top Inbuilt DataSets in Scikit-Learn Library
Some Top Inbuilt Datasets are mentioned below:
It is one of the most famous datasets in machine learning. It consists of 150 samples of iris flowers, with each sample containing four features: sepal length, sepal width, petal length, and petal width. The task is to classify these samples into one of three species: Iris Setosa, Iris Versicolor, or Iris Virginica.
We can easily load iris dataset using Scikit-Learn’s load_iris() function.
After loading the dataset, it is important to explore its structure. We can inspect the feature names, target names, and even visualize the data using scatter plots.
Output:
This dataset is designed for regression tasks. It consists of 442 samples with 10 features each, representing different factors like age, sex, body mass index (BMI), blood pressure, and blood serum measurements. The target is a quantitative measure of disease progression one year after baseline.
We can load the Diabetes dataset using the following command:
We can understand the distribution of the data and the relationships between features and the target variable.
Output:
This dataset is a collection of 8x8 pixel images of handwritten digits from 0 to 9. Each image is represented as a flattened 64-feature vector. The goal is to classify each image into one of the ten digit classes.
We can load the Digits dataset using:
We can visualize the images to better understand the dataset.
Output:
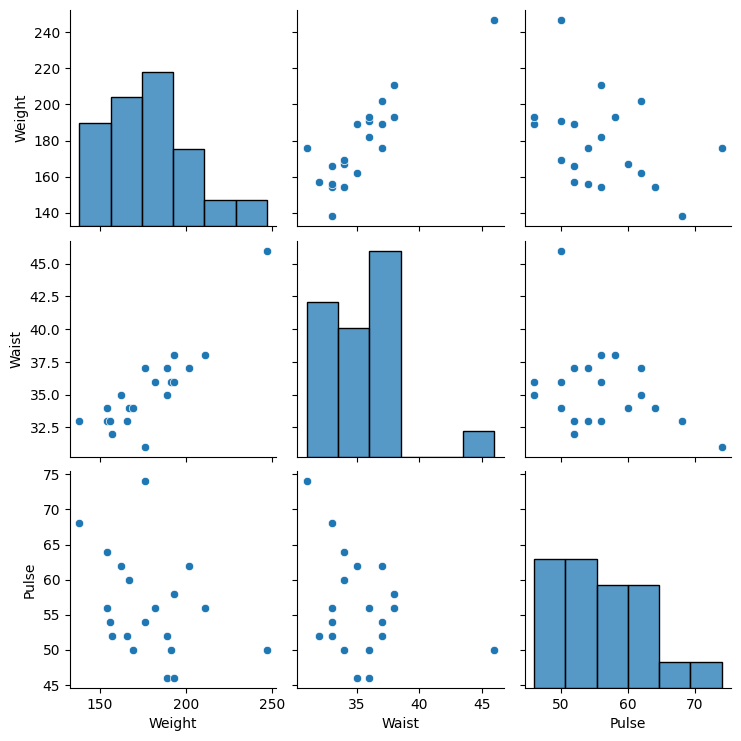
This dataset is a multivariate regression dataset that includes three exercise variables (chin-ups, sit-ups, and jumps) and three physiological measurements (weight, waist, and pulse). The goal is to predict the physiological measurements based on the exercise data.
We can load the Linnerud dataset using:
Given its small size, we can visualize Linnerud dataset:
Output:
This dataset consists of chemical analysis results for wines grown in a specific region of Italy. The task is to classify the wine samples into one of three cultivars based on their chemical properties.
We can load the Wine dataset using:
It is useful to see how these features relate to the target classes.
Output:
This dataset is a large database of handwritten digits used extensively in the field of machine learning and computer vision. It contains 70,000 28x28 pixel grayscale images of digits, with the goal being to classify them into their respective digit classes (0-9).
The MNIST dataset can be loaded using:
We can visualizing some of the digit images which can give us insights into the dataset:
Output:
The Scikit-learn library is a collection of inbuilt datasets that are important for learning and experimenting with various machine learning techniques. Each dataset present in this library serves a unique purpose, whether it’s for practicing classification, regression, or clustering algorithms. These datasets are not tools are not used by beginners, but also used by experienced practitioners to test new algorithms and approaches. After working with different datasets such as Iris, Diabetes, and Wine, we can grasp the fundamentals of data exploration and model building.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}