 |
VOOZH | about |
|
VOOZH | about |
Introducing the EcoSight Analytics by our team for the GeeksforGeeks EcoTech Hackathon. Our project combines a carbon footprint calculator, emission reduction tips, satellite image classification, and air quality index analysis empowering users to make informed decisions for a sustainable future. With interactive visualizations and a technology stack including Python, Django, and HTML, CSS, JavaScript for our project, it promotes greener lifestyles and fosters global environmental awareness. You can test it here.
Table of Content
The environmental issues our planet grapples with are manifold, ranging from the relentless menace of climate change to the alarming decline in biodiversity, the pervasive pollution problem, and the ever-depleting natural resources. These challenges underscored the urgency for our tech-savvy generation to step up and make a difference. In this context, Data Science emerged as a potent ally, offering analytical tools and machine learning techniques that could revolutionize our approach to these pressing issues.
What made EcoTech unique was the autonomy given to participants in choosing their datasets. This freedom enabled us to address issues that personally resonated with us, giving us a sense of ownership and passion for our projects. Whether we were crafting predictive models, delving deep into complex datasets, or uncovering valuable insights, the potential of Data Science was on full display.
But our responsibilities did not stop at analysis and model training. We were tasked with a crucial step: deploying our data-driven solutions to websites. This step ensured that our innovative solutions were not confined to the realm of theory but were accessible to a wider audience, bringing real-world relevance to our work.
EcoTech was a collaborative effort that epitomized the spirit of innovation, cooperation, and change. The judging criteria, which included innovation in projects, the usability and responsiveness of deployed websites, and the adept use of algorithms and data science techniques, emphasized the holistic nature of the event. We weren't just showcasing technical expertise; we were working together to create practical solutions that could make a real impact in the journey toward a sustainable environment.
EcoTech emerged as an embodiment of the belief that Data Science can be a force for good. It was a collective effort that showcased how, when harnessed effectively, data has the potential to drive positive change and transform our world. This hackathon was more than just a competition; it was a critical step in the global movement towards a more sustainable future.
Github repository: Here
Project website: EcoSight
Video presentation: Here
Our overall procedure included a few steps, and this could be explained very easily via a flowchart:
Even though we had multiple steps in between, which are well described in the sections below, this is just for a quick check of the overall steps.
One of the most challenging tasks in this project was to fetch data for this section of the project. Even though there were many sites offering data regarding carbon emissions, most of them were paid and they didn't qualify the needs of our project. After facing such challenges, we found out a few numbers of websites, which contained quality data which we required.
The sources include:
By the use of these sources we got our data in a kind of raw format, which was further preprocessed to get it into some work.
These datasets contained multiple features, the data we obtained from OurWorldInData contains features such as co2 emissions, co2 emissions per capita, co2 emissions by natural gas, and co2 emissions by coal per annum, of multiple countries. It contains multiple other features which we wouldn't have required for this project, so we dropped those features. Moreover, the dataset contains very old data as well, (as old as 1850s), we filtered out the data to only to the most recent years, so that there's least inaccuracy.
Besides this, we also obtained data from Statistica and Dewesoft, which was already in a pretty much clean format, so we didn't need to preprocess it much, we just extracted the features we required. They contained data about electricity prices of many countries and most common source of electricity in those countries respectively.
We also added a row called Avg , which contains the average value for each column, this would be used just in case if the user's specified country is not found in the data.
Here is the code to add the new row:
We didn't train any ML model for this section of our project, it was something which you can call automated Data analysis, we already have the data and on the basis of the inputs of a user, we calculate the carbon emissions annually , we also calculate in what percentages are electricity bills, gas bills etc. contributing to their annual emissions, this way the users are aware on how they can further reduce their emissions.
We also done some research on this topic and found out a few values, for example how many Co2 is produced when 1 KwH electricity is produced. We utilized these values to find out the annual carbon emissions of the users.
Here is a function which we need before the main function, this finds the per capita emissions of the users belonging to a particular country:
NOTE: here the variable "d" refers to the dataset, you can check the code in details in our github repository.
The main function which does the overall calculation is here:
Demo Input:
Output:
4.65
That's all about the carbon footprint calculator, let's move to the other sections of the project.
A Short way of explaining everything in this section:
We used the given dataset in this project section so we didnt need to find anything else.
We used this dataset from kaggle: here to train our model. It contains more than 40,000 images.
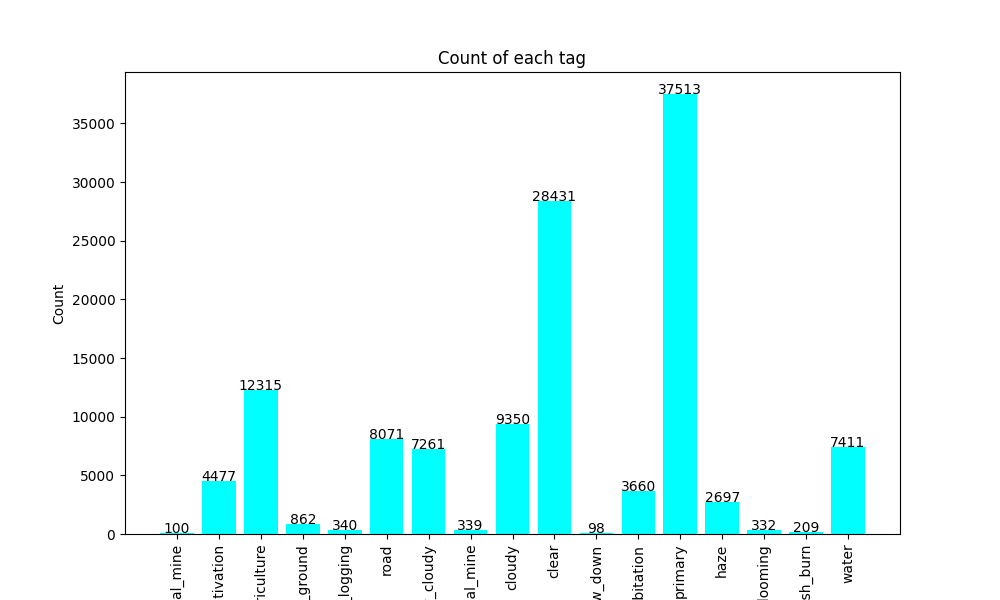
All of the images were classified on the basis of 17 tags such as "road", "agriculture", "slash and burn" etc.
Here in this project, we have used ResNet50 as a base model.
ResNet50: ResNet-50 is a convolutional neural network (CNN) that is 50 layers deep and is used for computer vision applications.
In between, we performed a lot of data exploration, and a few steps were taken to modify the data for our use.
We added 2 layers and 1 output layer using the following code:
We also used average pooling to optimize training procedure.
to avoid interruptions, we freeze the model:
Here we have first converted the image to a NumPy array and then started predicting the probabilities using it.
Output:
In this section, we have used keras' own model saving format, that is as a .h5 file.
You can also use the following code to save your keras model in a similar way:
Programming Language: Python
Platform for analysis and model training: Jupiter Notebook
Libraries used: Pandas , Numpy , Seaborn , Matplotlib , Scikit-learn , Joblib
We used the given dataset in this project section so we didn't need to find anything else.
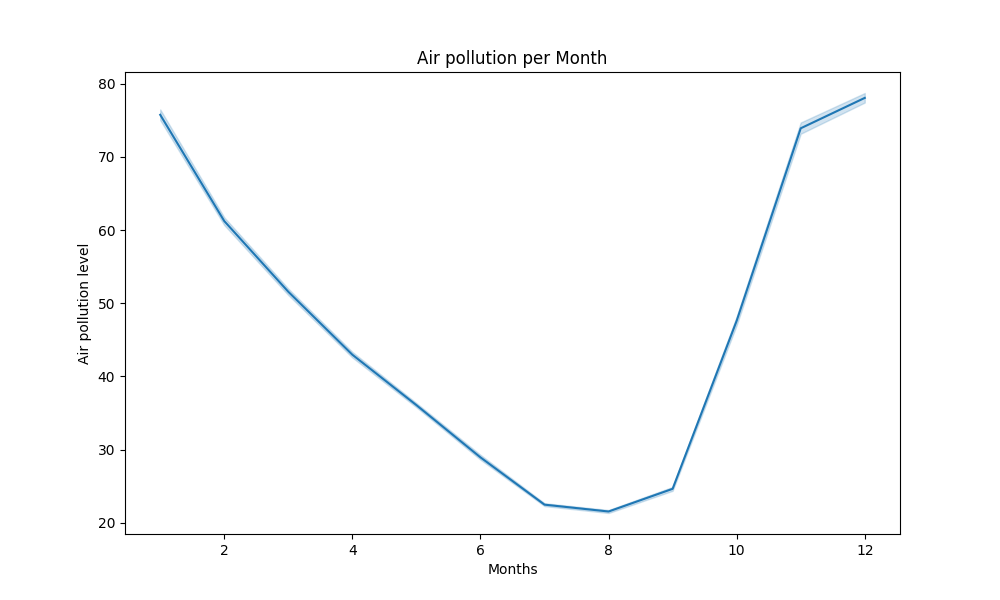
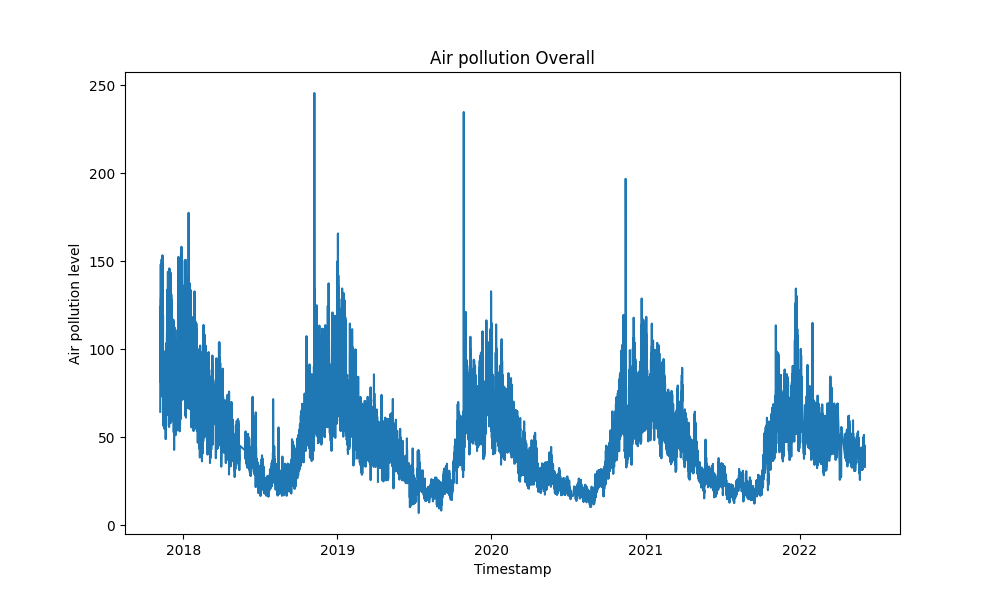
We used this dataset from kaggle: here to train our model. It contains data from 2017-2022 about AQI(air quality index) of India.
In this section, our main objective was to find out different insights, however we also trained a model additionally.
Output:
Output:
Output:
Output:
Output:
Output:
Note: You may need to change some arguments in the above code to make a similar graph for your project, in case you want to create something exactly similar, you may refer to this.
Our model was pretty much satisfactory considering the data size and other factors, we have calculated the MSE, RMSE , MAE , and R - Squared error for model evaluation and the values are as follows:
Mean Squared Error: 21.793092876871878
Root of Mean squared Error: 4.668307281753407
Mean Absolute Error: 2.7221482617304416
R- Squared error: 0.9646128599076852
And for saving it we have used Joblib. even though the file format we used was Pickle, but Joblib was much more efficient than the Pickle module itself. However, due to its extremely large size we used an additional argument called "compress" which allows us to compress our model. Here is a demo code for it:
A Short way of explaining everything in this section is:
Not much insights were found in this, we trained a deep learning model instead.
You can simply access our project website here.
After visiting there, you can hover your mouse over the "Project" section to see our project.
You can choose any particular project you want to visit and explore:)
All the steps to use are completely user-friendly so it isn't difficult at all.
Now, if you want to test the models locally in your computer you can follow the upcoming steps.
You can download the model directly from here.
Once you install it, please install a few libraries (make sure to have an internet connection), to do so , you may run these following commands in your command prompt:
Once, you're done, create a new python file and run this following code:
make sure to keep airQualityModel.pkl near your python script, else you can even mention your custom path.
Hope you like our model:)
You can download the model from here.
Once you install it, please install a few libraries (make sure to have an internet connection), to do so , you may run these following commands in your command prompt:
Once, you're done, create a new python file and run this following code:
make sure to keep SuperImpModel.h5 near your python script, else you can even mention your custom directory.
Hope you like our model:)
Our project promotes sustainable environmental development and also features multiple applications such as a carbon footprint calculator, so that people are aware of their own carbon emission contributions, not only does it calculate the carbon emissions it also suggests recommendations on how we can improve ourselves to have a better future!
Our project also has a Satellite image classification model which basically classifies the situation of any satellite image given to it, this will classify the probability of that particular area of having pollution, water, mine etc.
This can be used to identify your locality in a better way.
That's not all, we also analyzed the air pollution index data from 2017 to 2022 and drew out multiple helpful insights, you can check the overall analysis too! This also has a predictive model to find out upcoming air pollution indices especially in India, the model isn't available to run on the website, but you can run it locally in your computer (instructions are given near the Jupyter notebook, or you can check the other questions too)
You are already in the correct place; you can view this overall repository to find out our work.
Due to GitHub restrictions, we can't upload this file here as its quite large, but you can check the python notebook used to make it in the AirQuality folder.
We are using python as a language for the overall logic, and we are also using JavaScript in web development. For non-programming languages we are using HTML and CSS for web development. When it comes to libraries, we are using matplotlib and seaborn because of their wonderful capabilities of creating visualizations, we are also using pandas and NumPy for data management, TensorFlow Keras for deep learning and Scikit-Learn for machine learning.
For the backend and server hosting we are using free tier of python anywhere. As a framework we are working with Django.
Our project is solely made for sustainable environment development, we are creating it on the occasion of a wonderful hackathon organized by Geeksforgeeks which is called EcoTech, but besides for the hackathon we are also going to maintain this site after, and further developmental plans would be there for this website.
We are going to maintain our website even after this hackathon ends, we already have plans like tourism recommendation system, social media updates on ecology, and many more! the updates would be coming soon be ready!
We were really concerned about our environment, moreover due to the beautiful theme of the hackathon organized by GeeksForGeeks, we thought and found out the actual reasons for environmental degradation. Some Key factors are deforestation, and carbon emissions. Our project exactly aims to spread awareness on that issue.
In conclusion, the sustainable development of our ecosystem is not just a vision; it's a tangible reality that we are actively shaping through innovation and collective efforts. Our website, equipped with features like Satellite Image Classification, Carbon Footprint Calculator, and Air Quality Index Analysis, is a testament to our commitment to this cause. As we navigate the intricate web of data and technology, we discover the means to harmonize our existence with nature.
While our world is unmistakably progressing towards sustainability, the urgency of our situation cannot be overstated. Climate change and ecological degradation continue to challenge our planet. We must act swiftly, collectively, and decisively to preserve the delicate balance of our environment. Our mission is to not only provide tools for understanding and mitigating environmental impact but also to inspire action.
By embracing sustainable choices and advocating for change, we can accelerate this global transformation. Together, we have the power to safeguard our planet for generations to come. Let's work tirelessly, innovate relentlessly, and inspire one another to move swiftly towards a more sustainable future. Our planet's well-being depends on it.
We are thankful to all the data sources through which we have accessed the datasets, here are the sources:
We would like to express our sincere gratitude to GeeksforGeeks for organizing the hackathon that inspired this website. The hackathon was a well-organized and challenging event that provided us with the opportunity to learn new skills, collaborate with talented individuals, and develop this website.
We would also like to thank the following people for their support and guidance throughout the development of this website:
Without your help and support, this website would not have been possible. Thank you!
We would like to give special thanks to GeeksforGeeks for organizing the hackathon that inspired our website. GeeksforGeeks is a leading online platform for learning computer science and programming. It offers a wide range of resources, including tutorials, articles, practice problems, and more. We are grateful for the opportunity to have participated in the hackathon and to have learned so much from the experience.
Thank you for reading this article:)
{kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
-(1).png){kind=link}
{kind=link}
.png){kind=link}
{kind=link}
.png){kind=link}