 |
VOOZH | about |
|
VOOZH | about |
The ReLU (Rectified Linear Unit) is one of the most commonly used activation functions in neural networks due to its simplicity and efficiency. It is defined as:
This means it ranges from [0, ∞) i.e for any input value x, it returns x if it is positive and 0 if it is negative. But this approach causes some issues.
While ReLU is widely adopted it comes with some drawbacks especially during training deep networks:
To overcome these limitations leaky relu activation function was introduced.
Leaky ReLU is a modified version of ReLU designed to fix the problem of dead neurons. Instead of returning zero for negative inputs it allows a small, non-zero value. It introduces a slight modification to the standard ReLU by assigning a small, fixed slope to the negative part of the input. This ensures that neurons don't become inactive during training as they can still pass small gradients even when receiving negative values.
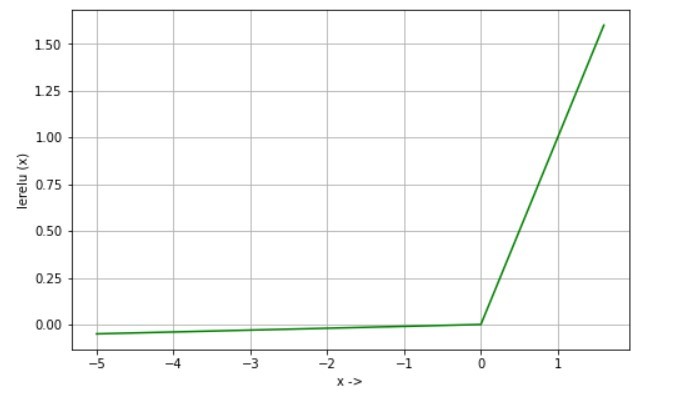
Its equation is:
and its graph is:
👁 Image| Feature | ReLU | Leaky ReLU |
|---|---|---|
Output for x > 0 | x | x |
Output for x < 0 | 0 | x (small negative value) |
Slope for x < 0 | 0 | Small constant (e.g., 0.01) |
Risk of Dead Neurons | High | Low |
Learning Capability | Stops for negative inputs. | Continues learning for all inputs. |
Complexity | Very Simple | Slightly more complex. |
While not always necessary switching to Leaky ReLU can improve learning dynamics and lead to better model performance where ReLU fails to activate certain neurons.
{kind=link}
{kind=link}