 |
VOOZH | about |
|
VOOZH | about |
Different performance metrics are used to evaluate different Machine Learning Algorithms. In case of classification problem, we have a variety of performance measure to evaluate how good our model is. For cluster analysis, the analogous question is how to evaluate the “goodness” of the resulting clusters?
Why do we need cluster validity indices ?
Generally, cluster validity measures are categorized into 3 classes, they are -
Besides the term cluster validity index, we need to know about inter-cluster distance d(a, b) between two cluster a, b and intra-cluster index D(a) of cluster a.
Inter-cluster distance d(a, b) between two clusters a and b can be -
Intra-cluster distance D(a) of a cluster a can be -
Now, let's discuss 2 internal cluster validity indices namely Dunn index and DB index.
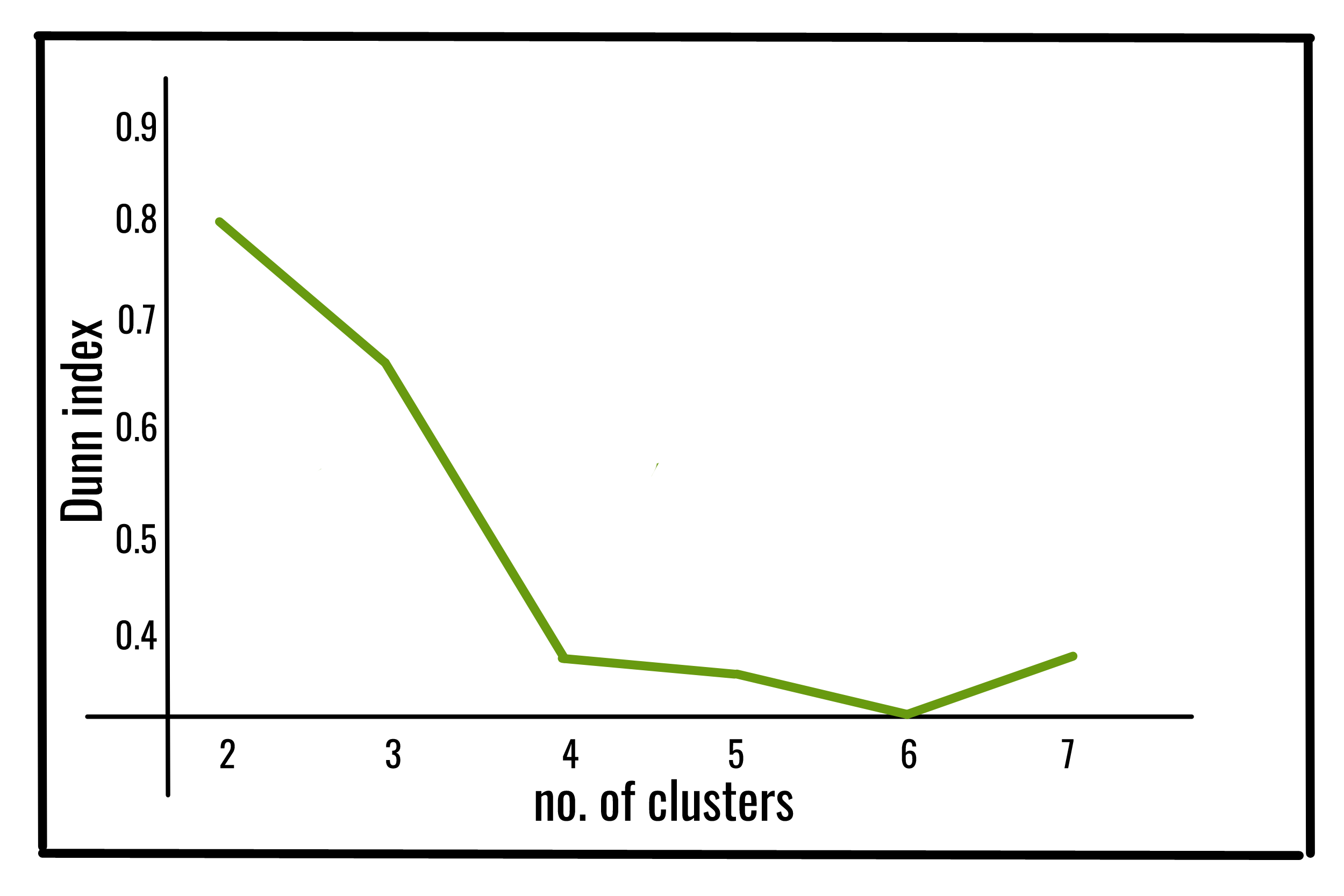
The Dunn index (DI) (introduced by J. C. Dunn in 1974), a metric for evaluating clustering algorithms, is an internal evaluation scheme, where the result is based on the clustered data itself. Like all other such indices, the aim of this Dunn index to identify sets of clusters that are compact, with a small variance between members of the cluster, and well separated, where the means of different clusters are sufficiently far apart, as compared to the within cluster variance.
Higher the Dunn index value, better is the clustering. The number of clusters that maximizes Dunn index is taken as the optimal number of clusters k. It also has some drawbacks. As the number of clusters and dimensionality of the data increase, the computational cost also increases.
The Dunn index for c number of clusters is defined as :
where,
Below is the Python implementation of above Dunn index using the jqmcvi library :
Output:
0.67328051
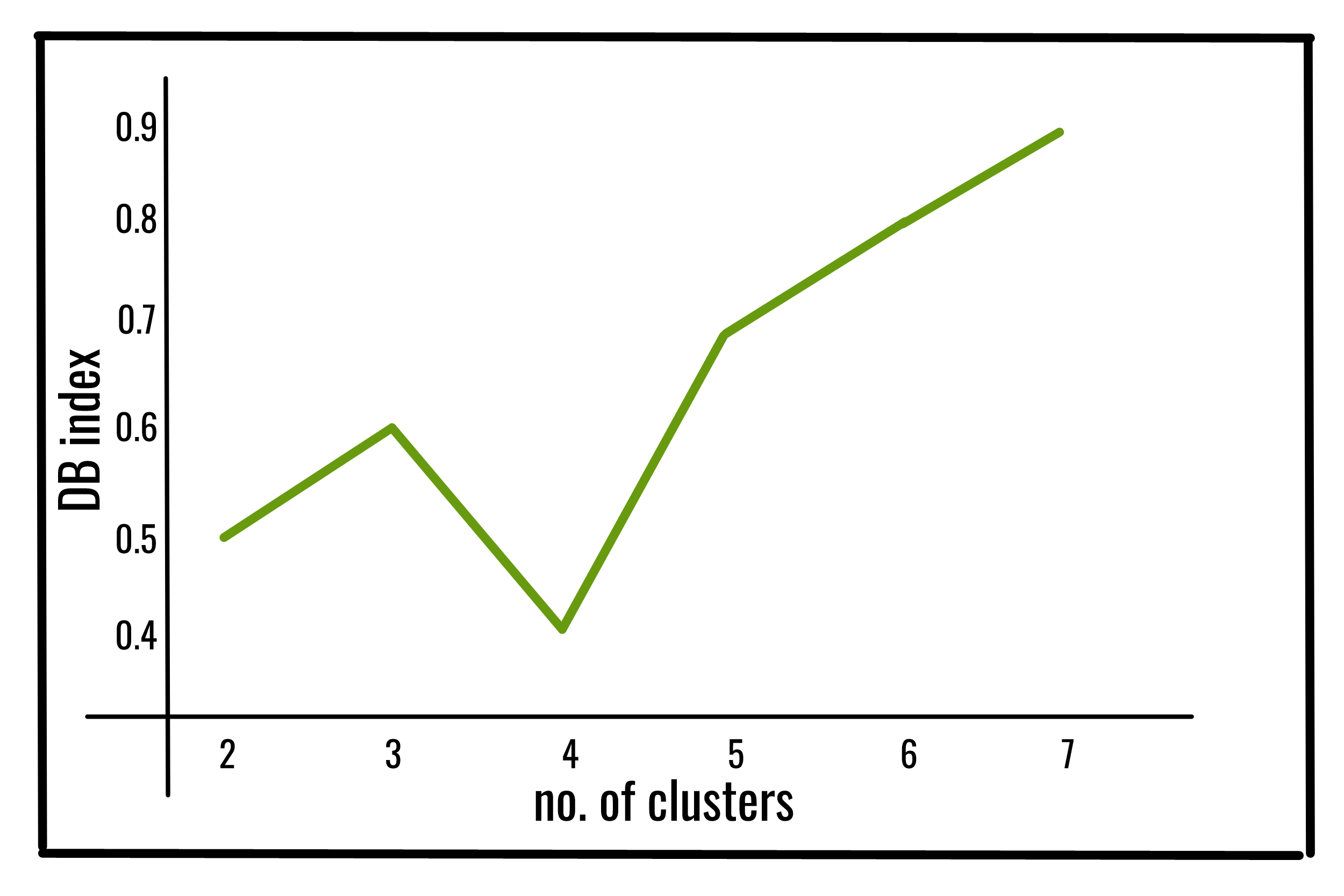
The Davies–Bouldin index (DBI) (introduced by David L. Davies and Donald W. Bouldin in 1979), a metric for evaluating clustering algorithms, is an internal evaluation scheme, where the validation of how well the clustering has been done is made using quantities and features inherent to the dataset.
Lower the DB index value, better is the clustering. It also has a drawback. A good value reported by this method does not imply the best information retrieval.
The DB index for k number of clusters is defined as :
where,
Below is the Python implementation of above DB index using the sklearn library :
Output:
0.36628770
References:
http://cs.joensuu.fi/sipu/pub/qinpei-thesis.pdf
https://en.wikipedia.org/wiki/Davies%E2%80%93Bouldin_index
https://en.wikipedia.org/wiki/Dunn_index
https://pyshark.com/davies-bouldin-index-for-k-means-clustering-evaluation-in-python/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
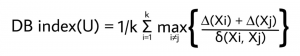{kind=link}
{kind=link}