 |
VOOZH | about |
|
VOOZH | about |
Scikit-Learn, a powerful and versatile Python library, is extensively used for machine learning tasks. It provides simple and efficient tools for data mining and data analysis. Among its many features, the fit() method stands out as a fundamental component for training machine learning models.
This article delves into the fit() method, exploring its importance, functionality, and usage with practical examples.
fit() MethodThe fit() method in Scikit-Learn is used to train a machine learning model. Training a model involves feeding it with data so it can learn the underlying patterns. This method adjusts the parameters of the model based on the provided data.
The basic syntax for the fit() method is:
model.fit(X, y)X: The feature matrix, where each row represents a sample and each column represents a feature.y: The target vector, containing the labels or target values corresponding to the samples in X.fit() method adjusts the model parameters based on the input data (X) and the target values (y).Let's consider a simple example of linear regression to understand how the fit() method works.
Step 1: Import the necessary libraries
import numpy as np
from sklearn.linear_model import LinearRegression
Step 2: Create Sample Data
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([1.5, 3.1, 4.5, 6.2, 7.9])
Step 3: Initialize the model
model = LinearRegression()Step 4: Train the model
model.fit(X, y)Step 5: Make Predictions
predictions = model.predict(X)In this example, model.fit(X, y) trains the linear regression model using the feature matrix X and the target vector y.
Output:
fit() MethodWhen the fit() method is called, several internal processes occur:
The fit() method is a part of various machine learning models in Scikit-Learn. Here are some common examples:
Output:
Support Vector Machines (SVM):
Output:
Decision Trees:
Output:
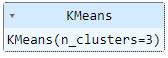
K-Means Clustering:
Output:
Before calling the fit() method, it’s crucial to preprocess the data. This includes handling missing values, scaling features, and encoding categorical variables.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
Properly training a model involves balancing between overfitting (model too complex) and underfitting (model too simple). Techniques like cross-validation and regularization can help mitigate these issues.
Cross-Validation:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5)
Regularization:
from sklearn.linear_model import Ridge
model = Ridge(alpha=1.0)
model.fit(X_train, y_train)
The fit() method in Scikit-Learn is essential for training machine learning models. It takes the input data and adjusts the model parameters to learn patterns and relationships. By understanding the workings of the fit() method, you can effectively train various machine learning models and optimize their performance. Proper data preprocessing, model selection, and evaluation techniques are vital to successful model training and deployment.
In summary, the fit() method is a cornerstone of Scikit-Learn's functionality, enabling the creation of powerful and accurate machine learning models with relatively simple and intuitive code. By mastering this method, you can harness the full potential of Scikit-Learn for your data science and machine learning projects.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}