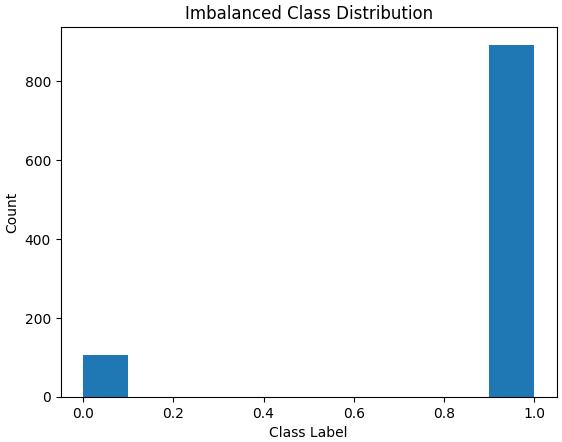
Imbalanced data occurs when one class has far more samples than others, causing models to favour the majority class and perform poorly on the minority class. This often results in misleading accuracy, especially in critical applications like fraud detection or medical diagnosis.
ML models tend to get biased toward the majority class and predict it more frequently.
Minority class instances may be treated as noise, causing the model to overlook them.
Accuracy becomes misleading because the model performs well only on the dominant class.
Skewed decision boundaries lead to poor generalisation and weak performance on minority class predictions.
Techniques to Handle Imbalanced Data
1. Use Better Evaluation Metrics
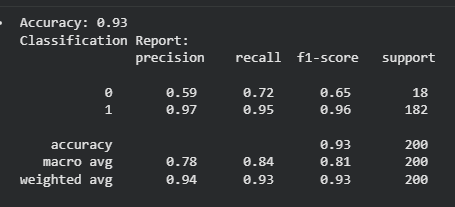
Accuracy is not a reliable metric for imbalanced datasets because a model can predict only the majority class and still achieve high accuracy. Instead, metrics like Precision, Recall and F1-score give a clearer picture of performance.
Precision measures how many predicted positives are actually correct.
Recall measures how many actual positives the model correctly identifies.
F1-score is the harmonic mean of precision and recall and is widely used for imbalanced datasets.
Precision and F1 score decrease with more false positives while recall and F1 score drop when minority class samples are missed. F1 score improves only when both precision and recall increase making it ideal for imbalanced datasets.
2. Resampling Techniques
Resampling adjusts the size of classes to make them more balanced.
Oversampling: Duplicates or generates minority class samples to help the model learn more patterns.
Undersampling: Removes majority class samples to balance the dataset and give equal importance to all classes.
Implementing Resampling
Creates an imbalanced binary dataset with one minority and one majority class using synthetic data.
Prints the original number of samples in each class before balancing.
Applies oversampling to duplicate minority class samples and balance the dataset.
Uses undersampling to reduce majority class samples and achieve class balance.
Balanced Bagging Classifier is an ensemble technique used to handle imbalanced datasets. It works like Bagging but balances each bootstrap sample so that minority classes are not ignored during training. Standard models favour the majority class due to which minority class predictions become poor. Balanced Bagging Classifier resamples data internally to fix this problem.
Implementing Balanced Bagging Classifier
Here in this code we create an imbalanced dataset and train a Random Forest model using balanced bootstrapped samples so that both majority and minority classes are learned fairly. The model is then evaluated on test data to check improved performance on the minority class.
Step 1: Import Required Libraries
make_classification creates synthetic imbalanced data
BalancedBaggingClassifier helps handle class imbalance
SMOTE is a data level technique used to handle imbalanced datasets by creating new synthetic samples for the minority class instead of duplicating existing ones. In SMOTE a minority class data point is first selected then its k-nearest neighbors are identified and finally a new synthetic data point is generated between the selected point and one of its neighbors.
Handling Class Imbalance Using SMOTE
Creates an imbalanced binary dataset and splits it into training and test sets.
Displays the class distribution of the training data before applying SMOTE.
Applies SMOTE to generate synthetic minority samples and balance the training dataset.
Output:
Class distribution before SMOTE: Counter({np.int64(1): 713, np.int64(0): 87}) Class distribution after SMOTE: Counter({np.int64(1): 713, np.int64(0): 713})
5. Threshold Moving
In classification, models often give probabilities for each class. By default a probability above 0.5 is labeled as the positive class. However for imbalanced dataset this default may not work well.
To improve performance the classification threshold can be adjusted. A lower or higher threshold can help the model better detect the minority class or reduce false positives.
Ways to find the best threshold:
ROC Curve: Choose the threshold that balances true positive rate and false positive rate.
Precision-Recall Curve: Especially useful for imbalanced data to maximize precision and recall.
Grid Search / Range Testing: Experiment with multiple threshold values to find the one that gives the best performance metrics.
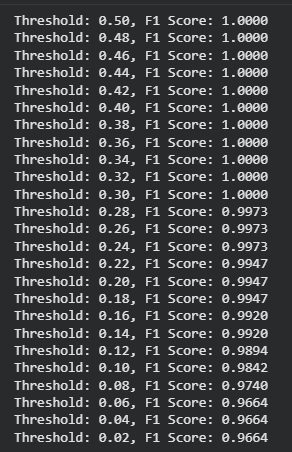
Implementing Threshold Tuning for Imbalanced Classification
This output shows how the F1 score changes with different classification thresholds. Higher thresholds (around 0.30–0.50) give perfect F1 scores (1.0), while lowering the threshold gradually reduces the F1 score, indicating a trade-off between precision and recall.
6. Using Tree Based Models
The hierarchical structure of tree-based models such as Decision Trees, Random Forests and Gradient Boosted Trees allows them to handle imbalanced datasets better than non-tree-based models.
Decision Trees: Decision trees create a structure resembling a tree by dividing the feature space into regions according to feature values. By changing the decision boundaries to incorporate minority class patterns, decision trees can react to data that is unbalanced. They might experience overfitting, though.
Random Forests: Random Forests are made up of many Decision Trees that have been trained using arbitrary subsets of features and data. Random Forests improve generalization by reducing overfitting and strengthening robustness against imbalanced datasets by mixing numerous trees.
Gradient Boosted Trees: Boosted Gradient Trees grow in a sequential fashion, with each new growth repairing the mistakes of the older one. Gradient Boosted Trees perform well in imbalanced circumstances because of their ability to concentrate on misclassified occurrences through sequential learning. Although they often work effectively, they could be noise-sensitive.
7. Using Anomaly Detection Algorithms
Anomaly or Outlier Detection algorithms are one class classification algorithms that helps in identifying outliers ( rare data points) in the dataset.
In an Imbalanced dataset, assume Majority class records as Normal data and Minority Class records as Outlier data.
These algorithms are trained on Normal data.
A trained model can predict if the new record is Normal or Outlier.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}