 |
VOOZH | about |
|
VOOZH | about |
Accuracy evaluates how well a machine learning model performs. It represents the percentage of correct predictions made by the model. While simple to calculate and understand, accuracy is most effective when the dataset is balanced.
In this article, we are going to learn how to measure the accuracy of the model and other evaluation metrics.
Accuracy is easy to understand and works well when the data is balanced i.e all classes in the dataset are equally represented. However accuracy isn’t always the best measure of performance. In datasets where one class dominates like 95% of cases being "negative" and only 5% "positive" then model predicting only the majority class would have high accuracy but wouldn’t solve the problem effectively.
To calculate accuracy we compare the model's predictions to the actual values. Count how many predictions were correct and divide that by the total number of predictions. we can break it down like this:
The full formula is:
For example, if a model is tested on 100 cases and gets 85 correct, the accuracy is:
You can also calculate accuracy easily with Python using libraries like scikit-learn:
Accuracy Score: 0.8
The accuracy paradox happens when a machine learning model seems to perform well because it has high accuracy but it’s not actually making useful predictions. This problem is common in datasets where one class appears much more frequently than others i.e it is a imbalanced datasets. In these cases the model may focus on predicting the majority class correctly but it fails to predict the minority class which is often more important.
Example: Imagine a health model predicting whether a patient has cancer:
A model that always predicts "healthy" would have 95% accuracy because it correctly identifies the majority class i.e healthy patients. However it would miss all cancer cases which is a serious problem. This high accuracy score gives a false sense of success and hides the model’s failure to predict the minority class.
Instead of relying on accuracy alone we use other metrics to evaluate your model more effectively:
In binary classification, the model predicts one of two possible classes, such as "spam" or "not spam." Accuracy is calculated as:
Example: Consider a spam filter where a high accuracy indicates the filter performs but if the dataset is imbalanced accuracy might not reveal the true performance. Precision and recall are often used alongside accuracy in such cases.
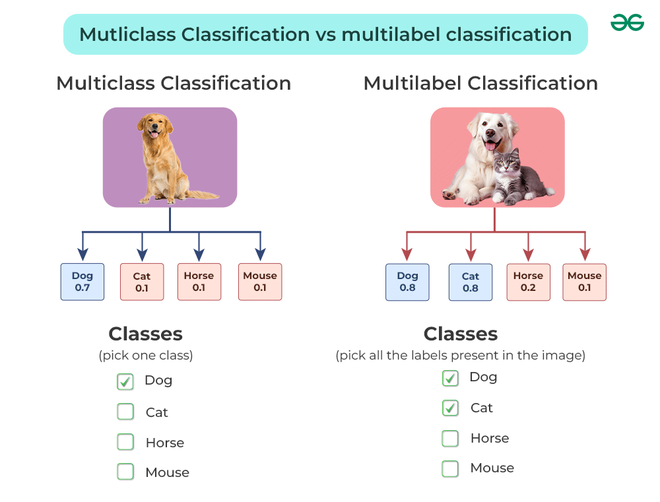
In multiclass classification the model predicts one of three or more classes such as classifying handwritten digits (0–9). Accuracy in this context is defined as:
where
Example: Confusion matrix for a multiclass classification problem:
Predicted A | Predicted B | Predicted C | Total | |
|---|---|---|---|---|
Actual A | 7 | 2 | 1 | 10 |
Actual B | 3 | 5 | 2 | 10 |
Actual C | 2 | 1 | 3 | 6 |
Total | 12 | 8 | 6 | 31 |
Correct predictions: 7 + 5 + 3 = 15
Total predictions: 31
Accuracy:
Result: The model achieved 48.3% accuracy.
In multilabel classification, a single instance can be associated with multiple classes at the same time. For instance, a news article might be labeled with categories like "Politics," "Economy," and "World."
Multilabel accuracy also referred to as the Hamming score is calculated in multilabel classification by comparing the number of correctly predicted labels to the total number of relevant labels.
Precision emphasizes the accuracy of positive predictions by calculating the ratio of correctly predicted positive instances to the total instances predicted as positive.
Recall measures the proportion of actual positive instances that the model correctly identified. It focuses on capturing as many true positives as possible.
The F1-Score combines precision and recall into a single metric by calculating their harmonic mean. It provides a balance between the two and is particularly useful when you need to account for both false positives and false negatives.
Accuracy is a good metric to use when you want to see how well our model is classifying data especially if our dataset is balanced, meaning all classes have similar amounts of data. It gives a simple measure of how many predictions are correct out of all predictions.
{kind=link}
{kind=link}