How to split a Dataset into Train and Test Sets using Python
Last Updated : 7 Apr, 2026
To build and evaluate a machine learning model, the dataset must be divided into two parts i.e one for training the model and another for testing its performance. This process helps measure how well a model works on unseen data. This is done to properly assess how well the model will perform in real-world scenarios.
The training set is used to learn patterns from the data.
The test set is used to evaluate how well the model performs on new data.
It prevents overfitting by avoiding training and testing on the same data.
It provides a realistic estimate of model accuracy.
It allows fair comparison between different models.
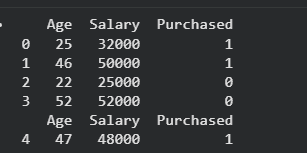
Method 1: Splitting Dataset Using train_test_split()
The train_test_split() function from scikit-learn is the most common and easiest way to split a dataset.
This shows the splitting of our dataset. Now let's see our models accuracy using logistic regression model.
Output:
Accuracy: 1.0
We can see our model is performing well after train and test split.
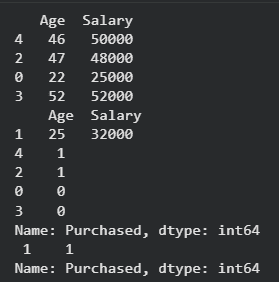
Method 2: Manual Splitting Using Indexing
Manual splitting means dividing a dataset into training and testing parts without using built-in ML functions like train_test_split(). This approach gives full control over how data is shuffled and split.

{kind=link}
{kind=link}
{kind=link}
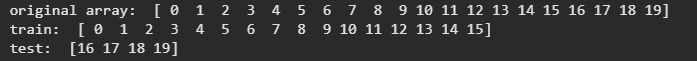{kind=link}