 |
VOOZH | about |
|
VOOZH | about |
The Vision API from Google Cloud has multiple functionalities. In this article, we will see how to access them. Before using the API, you need to open a Google Developer account, create a Virtual Machine instance and set up an API. For that, refer to this article.
We need to download the following packages -
pip install google.cloud.vision
The various services performed by Google Vision API are -
It can detect multiple faces in an image and express the emotional state of the faces.
Save the ‘credentials.json’ file in the same folder as the .py file with the Python code. We need to save the path of ‘credentials.json’ (C:\Users\…) as ‘GOOGLE_APPLICATION_CREDENTIALS’ which has been done in line-7 of the following code.
The above code detects multiple faces in a picture and determines the emotional expressions exhibited by the faces and whether any of the faces is wearing a headgear. It also returns the vertices which form a rectangle around the individual faces.
Lastly, it prints the percentage of surety with which the conclusions were drawn.
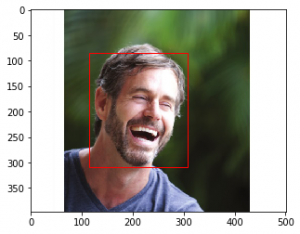
For example, when the following image is given as input -
Output:
Possibility of anger: VERY_UNLIKELY Possibility of joy: VERY_LIKELY Possibility of surprise: VERY_UNLIKELY Possibility of sorrow: VERY_UNLIKELY Vertices covering face: [(115, 84), (308, 84), (308, 309), (115, 309)] Confidence in Detection: 99.93739128112793%
Detects popular product logos present in an image.
The above code detects the logos of various companies in an image and prints the name of the companies. For example, when given the following image:
Output:
hp
Detects broad sets of categories in an image, which ranges from animals, trees to vehicles, buildings etc.
All possible labels or tags are attached to an image. For example, when the following image is given as input:
Output:
Street Neighbourhood Café Coffeehouse Sitting Leisure Tourism Restaurant Street performance City
Detects famous landmarks (mostly man-made) within an image.
The above code recognizes any famous landmark and also returns the location of that landmark using latitudes and longitudes. For example, when we input the following picture:
Output:
Victoria Memorial Latitude: 22.545121, Longitude: 88.342781
For more information, visit the Google Vision API documentation here.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}