 |
VOOZH | about |
|
VOOZH | about |
SVM is a type of supervised learning algorithm used in machine learning to solve both classification and regression tasks particularly effective in binary classification problems, where the goal is to classify data points into two distinct groups.
SVM interview questions test your knowledge of how SVM works, how to fine-tune the model, and its real-world uses. This article provides a list of SVM questions to help you prepare and show your skills.
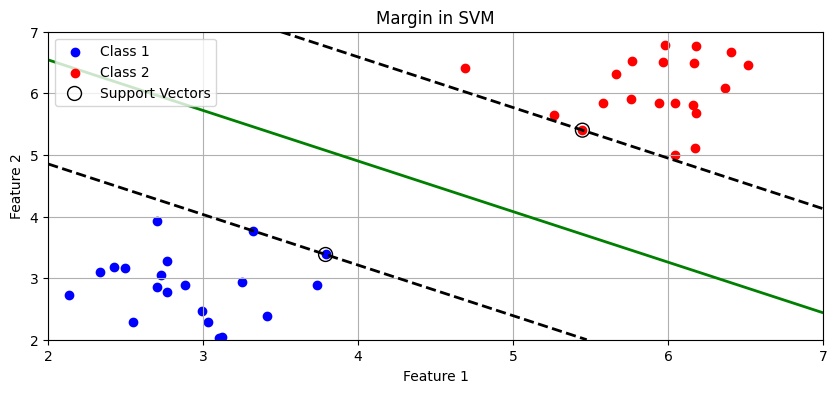
Core idea of Support Vector Machines (SVM) is to find an optimal hyperplane that separates data points of different classes in a feature space with the largest possible margin.
The key idea is to maximize the support vectors, as it improves the model's accuracy on unseen data.
Support vectors "support" the hyperplane and play a pivotal role in defining the SVM model's decision-making process. The key characteristics of support vectors include:
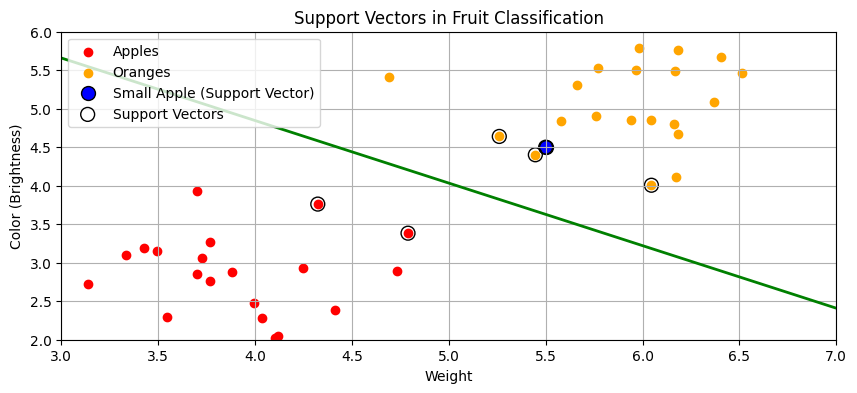
Bonus example: Imagine trying to classify fruits based on their weights and colors, with one class being for the apples and another being for the oranges.
If there’s a small apple that is similar in size and color to that of an orange, it might become a support vector because it’s close to the boundary separating the two classes. If this small apple is removed, then the boundary would shift towards where the small apple used to be. This would reduce the model's ability to accurately classify new fruits.
The small apple ( similar in size and color to an orange) near the orange cluster is highlighted as a potential support vector.
In SVM, the margin is thegap between the decision boundary and the support vectors.
Example: Let's illustrates the importance of maximizing the margin to achieve better generalization and reduce overfitting.
The main difference between hard margin and soft margin SVM is how they handle misclassifications.
Slack variables in SVM allow the model to accept some mistakes when the data can't be perfectly separated. They show how much a data point is misclassified or on the wrong side of the margin.
With slack variables, SVM can still find the best boundary by balancing between having a wide margin and minimizing errors. The C parameter controls how much misclassification (slack) is allowed, adjusting how strict the model is about getting the correct classifications.
In SVM, the decision boundary separates classes. For low-dimensional data, it's easy to visualize, but in high dimensions, it's harder to see.
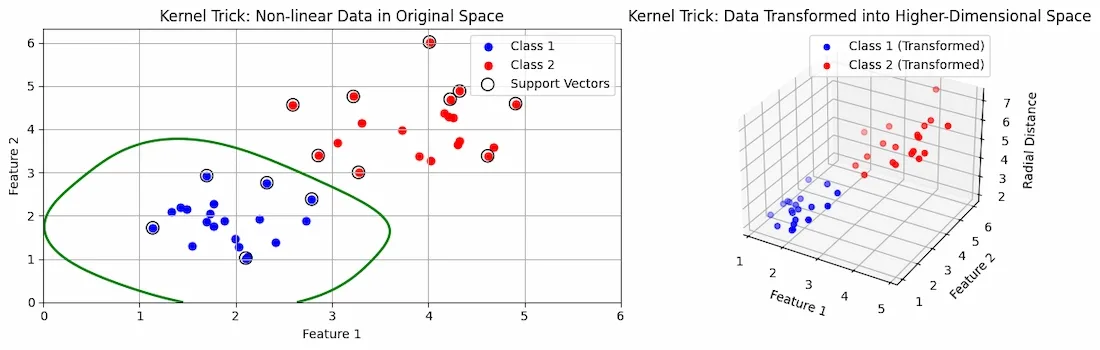
The kernel trick is a method used in SVM to handle non-linear data. It works by transforming the data into a higher-dimensional space where it’s easier to separate with a straight line.
But, instead of actually moving the data to this new space, the kernel trick uses a special math function to calculate the relationships between data points as if they were in that space. This makes it faster and helps SVM handle complex patterns. Common examples of kernels are the polynomial and radial basis function (RBF).
Hinge loss is a way to measure how wrong the SVM model’s predictions are. If a point is correctly classified and far enough from the decision boundary, the loss is zero. But if a point is misclassified or too close to the boundary, the loss increases. The SVM tries to minimize this loss while keeping the classes well separated.
The primal formulation is the straightforward way of solving a SVM problem by finding the decision boundary that separates the classes. The goal is to maximize the margin and minimize the misclassifications.
Dual formulation takes a different approach. It focuses on the relationship between the data points. It used Lagrange multipliers to make the problem easier to solve mathematically. It also allows the use of kernels for non-linear problems.
Lagrange Multipliers make it possible to handle complex problems with constraints in an organized way. In SVM, Lagrange multipliers are used to find the best decision boundary while respecting constraints like maximizing the margin.
These multipliers show which data points are most important for defining the boundary. The support vectors have non-zero multipliers, meaning they directly influence the boundary. Other points, which are farther away, have multipliers of zero and don’t affect the boundary. This way, SVM focuses only on the key points needed to create the best separation between classes.
The important parameters in SVM include C, kernel, and gamma, as they significantly influence the model's performance and ability to generalize.
To adapt SVM for imbalanced classes, you can adjust the class weights to make the model pay more attention to the minority class. This means giving more importance to misclassifications of the smaller class. Another option is to balance the classes by either adding more examples of the minority class (oversampling) or removing some from the majority class (undersampling).
Cost-sensitive learning in SVM addresses the issue of class imbalance by assigning higher penalties to misclassifications of the minority class during training. This approach prevents the model from being biased towards the majority class, which often occurs in imbalanced datasets.
Feature selection in SVM means picking the most important features for the model and leaving out the ones that don’t add much value.. Using too many unnecessary features can slow down the model and lead to overfitting. Methods like recursive feature elimination (RFE) help remove unnecessary features.
Overfitting in SVM happens when the model becomes too focused on the training data, fitting even the noise instead of general patterns. This usually happens with a high C value, which tries too hard to avoid mistakes.
To prevent overfitting, you can lower the C value to allow some mistakes, choose a simpler kernel, or use cross-validation to find the best settings. Regularizing the model and cleaning the data also help reduce overfitting.
SVM handles noise and outliers by using soft margins, which allows for some misclassifications making the model more flexible. The regularization parameter C controls the trade-off between having a large margin and allowing some errors.
Outliers can mess with the decision boundary, but techniques like cross-validation and kernel tricks help reduce their impact. Preprocessing steps like removing outliers (using methods like Z-score or IQR) and feature scaling make the model more stable and reliable.
SVM works well with high-dimensional text data by using features like TF-IDF or Word2Vec to represent the text as numbers. A challenge is that text data often results in sparse vectors, where many values are zero, slowing down training, however, SVM can handle sparse data effectively by using a linear kernel, regularization parameter (C), and feature selection to reduce irrelevant features. Proper tuning ensures efficient performance even with sparse data.
SVM, which is designed for binary classification, can be adapted for multi-class problems using two main methods:
In general, use OvO when you have fewer classes and OvA when there are many classes for better efficiency.
Support Vector Regression (SVR) is a type of SVM used for predicting continuous values, like predicting house prices or temperatures. Instead of drawing a boundary to separate categories, SVR tries to find the best line or curve that fits the data points as closely as possible.
It allows some margin of error to keep the model simple. SVR can handle both linear and more complex non-linear relationships, making it useful for a wide range of prediction tasks, especially with small or noisy data.
Evaluating the performance of an SVM model involves using a variety of metrics to assess how well the model generalizes to unseen data. The choice of metrics depends on the specific problem and dataset characteristics.
In classification, key metrics include accuracy, precision, recall, F1-score, confusion matrix, and ROC-AUC. For regression, common metrics are MAE (Mean Absolute Error), MSE (Mean Squared Error), and R² (R-squared).
{kind=link}
{kind=link}
{kind=link}
{kind=link}