 |
VOOZH | about |
|
VOOZH | about |
Clustering is a fundamental technique in unsupervised learning, widely used for grouping data into clusters based on similarity. Among the clustering algorithms, K-Means and its improved version, K-Means++, are popular choices.
This article explores how both algorithms work, their advantages and limitations, and how K-Means++ addresses the shortcomings of K-Means to achieve better clustering results.
K-Means clusters similar data points by initially selecting a specific number of starting points, known as centroids, at random. Each data point is then assigned to the nearest centroid, and the centroids are updated to the average position of the points assigned to them. This process continues iteratively until the centroids no longer change position or a predefined number of iterations is completed.
Let’s implement K-Means on a synthetic dataset to observe its behavior.
Output:
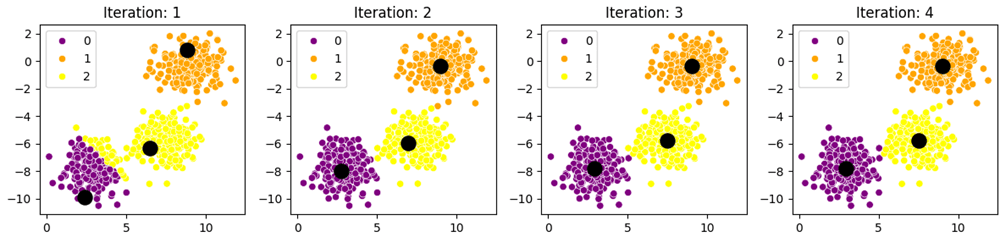
Converged after 7 iterationsRandom initialization can place centroids too close together, requiring more iterations and yielding suboptimal results.
K-Means++ is an enhanced version of K-Means designed to address the issue of random centroid initialization. It uses a more systematic approach to select initial centroids, ensuring they are well-distributed across the dataset.
Let’s implement K-Means++ on the same dataset to see its improved performance.
Output:
Converged after 4 iterations
K-Means++ method gives better results compared to the random method of K-Means. The K-Means++ method spreads the starting points farther apart which helps the algorithm work faster and find good clusters more quickly.
K-Means | K-Means++ | |
|---|---|---|
Centroid Initialization | Randomly selects initial centroids | Strategically selects well-spread initial centroids |
Cluster Quality | Depends on random initialization, may be suboptimal | Generally produces better clusters due to better starting points |
Convergence Speed | May converge more slowly | Faster convergence due to improved initialization |
Initialization Time | Quick and simple | Slightly slower due to additional calculations |
Risk of Poor Clustering | Higher due to random starting points | Lower due to systematic initialization |
Algorithm Complexity | Simpler and faster in initialization | Slightly more complex due to extra initialization step |
Both K-Means and K-Means++ are valuable clustering algorithms, but K-Means++ significantly improves upon K-Means by addressing the limitations of random initialization. Its systematic approach leads to faster convergence, fewer iterations, and more accurate clustering results. While K-Means may be preferred for simplicity and speed in initialization, K-Means++ is the better choice for practical applications requiring robust and high-quality clustering.
{kind=link}
{kind=link}
{kind=link}