 |
VOOZH | about |
|
VOOZH | about |
K-Medoids, also known as Partitioning Around Medoids (PAM), is a clustering algorithm introduced by Kaufman and Rousseeuw. It is similar to K-Means, but instead of using the mean of points as a cluster center, it uses an actual data point called a medoid.
A medoid is the most centrally located data point within a cluster. It minimizes the total dissimilarity with all other points in that cluster. The dissimilarity between a medoid Ci and an object Pi is given by:
The total cost (or objective function) of K-Medoids is defined as:
1. Initialize: Randomly select k data points from the dataset as initial medoids.
2. Assign Points: Assign each data point to the nearest medoid using a distance metric (e.g., Manhattan or Euclidean).
3. Update Step (Swap): For each medoid m, try swapping it with a non-medoid point ooo.
4. Repeat: Continue until no further cost reduction is possible.
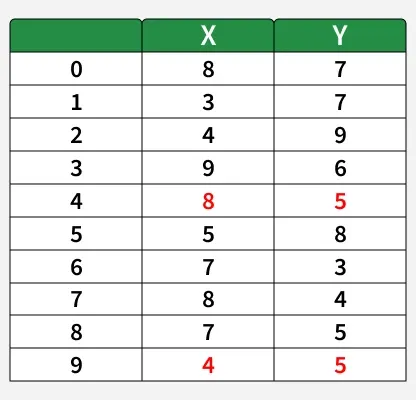
Let’s consider the following example.
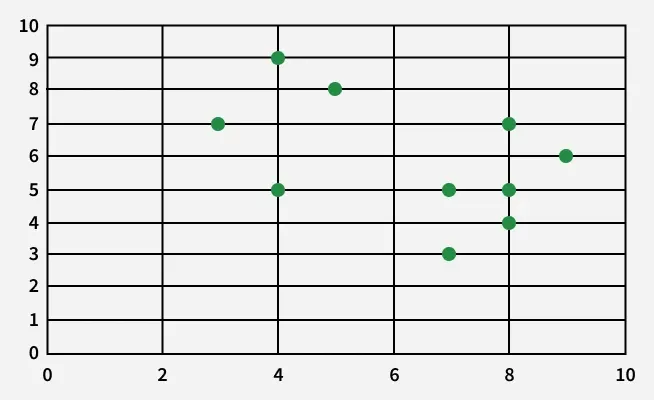
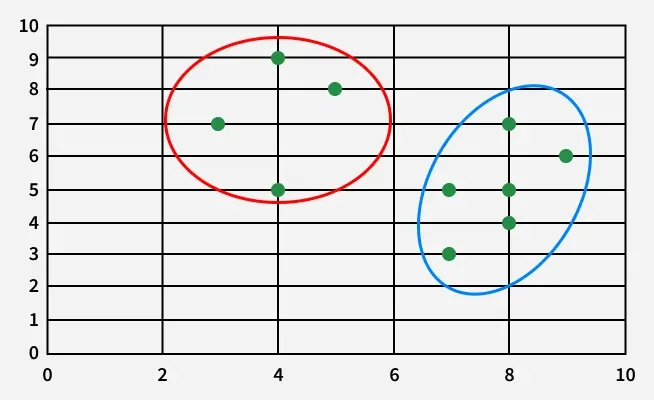
If a graph is drawn using the above data points, we obtain the following:
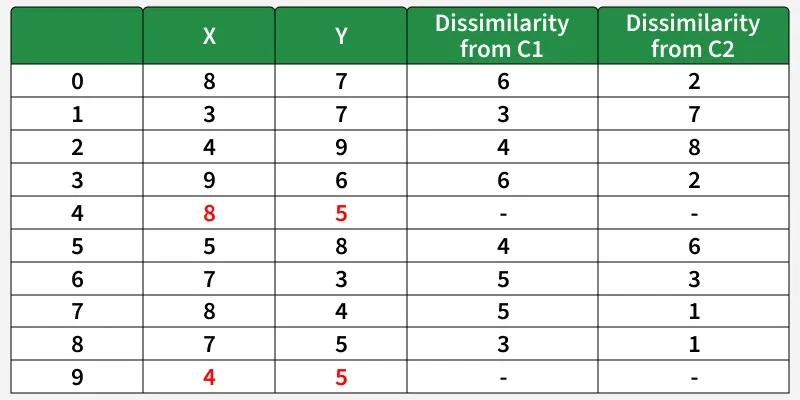
Let the randomly selected 2 medoids be: k=2 and let C1 = (4, 5) and C2 = (8, 5).
The dissimilarity of each non-medoid point with the medoids is calculated and tabulated:
We use the Manhattan distance formula to calculate the distance between medoid and non-medoid points:
Each point is assigned to the cluster of the medoid whose dissimilarity is lesser.
Cost = ( 3+ 4+ 4) +( 3+ 1+ 1+ 2+ 2) = 20
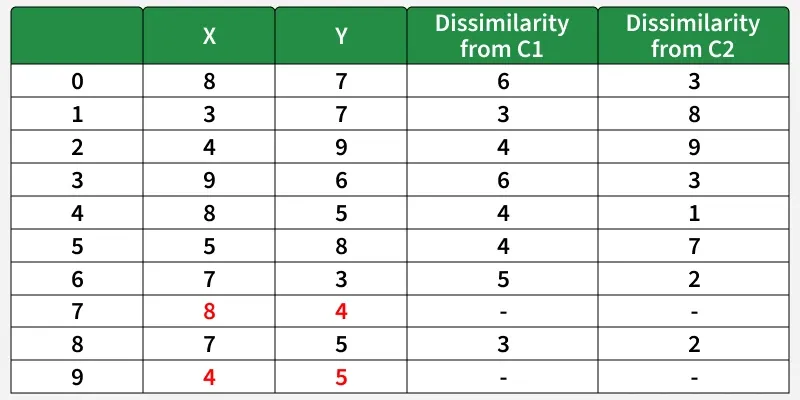
Now, randomly select one non-medoid point and recalculate the cost. Let the randomly selected point be (8, 4).
Each point is assigned to the cluster whose dissimilarity is lesser.
New Cost = ( 3+ 4+ 4) +( 2+ 2+ 1+ 3+ 3) = 22
Swap Cost = New Cost - Previous Cost = 22-20 = 2
Since 2 >0, the swap cost is not less than zero, so we undo the swap.
Hence, (4, 5) and (8, 5) are the final medoids.
The clustering is as follows:
The time complexity of the K-Medoids algorithm is:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}