 |
VOOZH | about |
|
VOOZH | about |
Markov Decision Process (MDP) is a framework for decision-making under uncertainty and is formally defined by a tuple (S, A, P, R, γ), representing states, actions, transition probabilities, rewards and the discount factor. It helps us answer questions like:
In artificial intelligence Markov Decision Processes (MDPs) are used to model situations where decisions are made one after another and the results of actions are uncertain. They help in designing smart machines or agents that need to work in environments where each action might led to different outcomes.
An MDP has five main parts:
1. States (S): A state is a situation or condition the agent can be in. For example, A position on a grid like being at cell (1,1).
2. Actions (A): An action is something the agent can do. For example, Move UP, DOWN, LEFT or RIGHT. Each state can have one or more possible actions.
3. Transition Model (T): The model tells us what happens when an action is taken in a state. It’s like asking: “If I move RIGHT from here, where will I land?” Sometimes the outcome isn’t always the same that’s uncertainty. For example:
This randomness is called a stochastic transition.
4. Reward (R): A reward is a number given to the agent after it takes an action. If the reward is positive, it means the result of the action was good. If the reward is negative it means the outcome was bad or there was a penalty help the agent learn what’s good or bad. Examples:
5. Policy (π): A policy is the agent’s plan. It tells the agent: “If you are in this state, take this action.” The goal is to find the best policy that helps the agent earn the highest total reward over time.
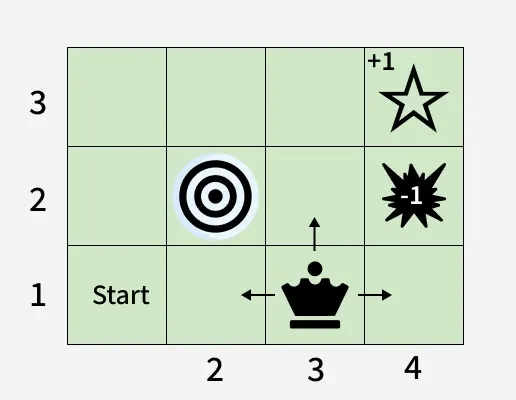
Let’s consider a 3x4 grid world. The agent starts at cell (1,1) and aims to reach the Blue Diamond at (4,3) while avoiding Fire at (4,2) and a Wall at (2,2). At each state the agent can take one of the following actions: UP, DOWN, LEFT or RIGHT
The agent’s moves are stochastic (uncertain):
{kind=link}
{kind=link}
{kind=link}