 |
VOOZH | about |
|
VOOZH | about |
The aim of the clustering process is to discover overall distribution patterns and interesting correlations among the data attributes. It is the task of grouping a set of objects in such a way that objects in the same group are more similar to each other than to those in other groups. Cluster analysis itself is not one specific algorithm, but the general task to be solved. It can be achieved by various algorithms that differ significantly in their understanding of what constitutes a cluster and how to efficiently find them. Popular notions of clusters include groups with small distances between cluster members, dense areas of the data space, intervals or particular statistical distributions. Here, we will discuss about the distance between the objects of the different clusters and the objects of the same clusters. We have two type of distance:
Let S and T are clusters formed using partition U. d(x, y) is the distance between two objects x and y belonging to S and T respectively. d(x, y) is calculated using well-known distance calculating methods such as Euclidean, Manhattan and Chebychev. |S| and |T| are the number of objects in clusters S and T respectively.
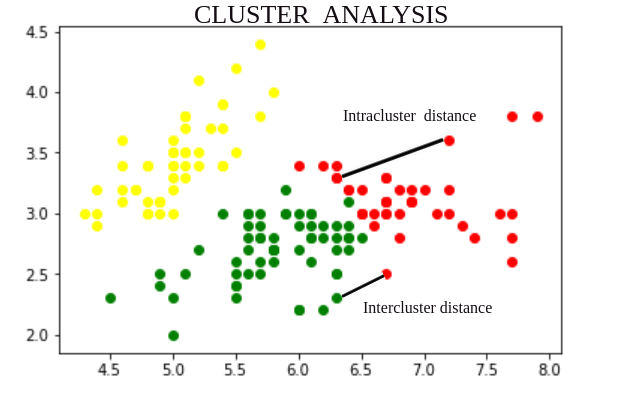
Intercluster distance is the distance between two objects belonging to two different clusters. It is of 5 types -
Intracluster distance is the distance between two objects belonging to same cluster. It is of 3 types -
👁 ImageNote: If a clustering algorithm makes clusters so that the Intercluster distance between different clusters is more and Intracluster distance of same cluster is less, then we can tell that it is a good clustering algorithm.
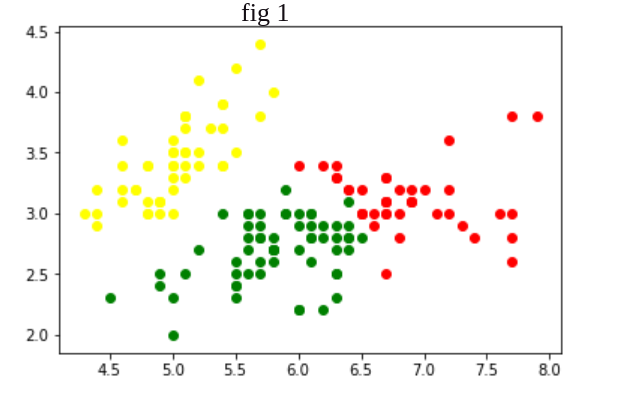
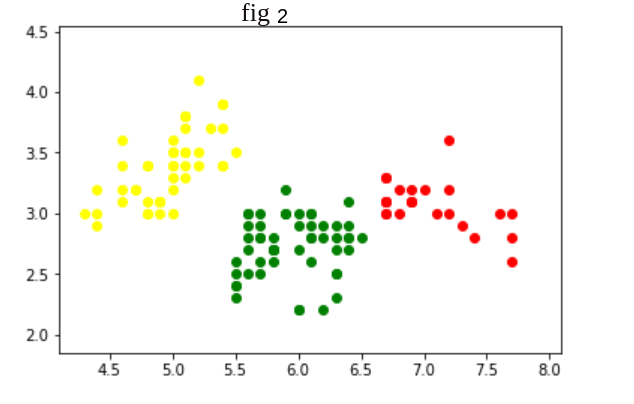
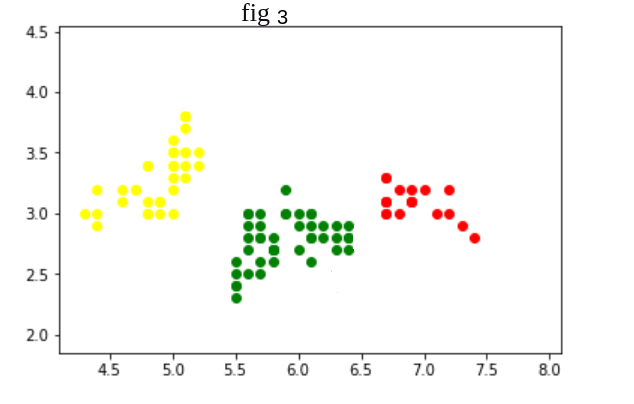
Here clustering algorithm in fig 3 is better than fig 2 and fig 1 as in fig 3 Intercluster distance is more and Intracluster distance is less.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}