Data refers to the set of observations or measurements to train a machine learning models. The performance of such models is heavily influenced by both the quality and quantity of data available for training and testing. Machine learning algorithms cannot be trained without data. Cutting-edge development in Artificial Intelligence, automation, and data analysis is powered mostly by vast sets of data.
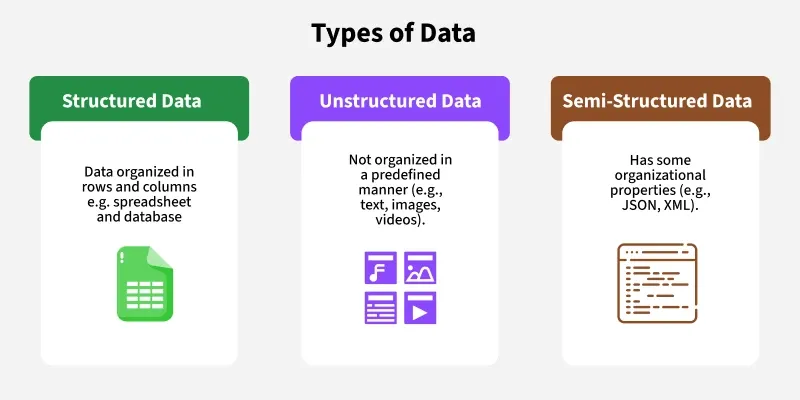
1. Structured Data: Tabular data, such as rows and columns, is used to organize and store structured data. Spreadsheets and databases frequently contain this type of data.
Usage: Useful in supervised learning tasks like regression and classification.
2. Unstructured Data: Processing unstructured data is more challenging because it lacks a preset structure.
Examples: Text files, pictures, videos, and audio files are a few examples.
Usage: Found in speech-to-text systems, image recognition, and natural language processing (NLP) applications.
3. Semi-Structured Data: This type of data falls somewhere between unstructured and structured data. It has organizational elements but does not fit nicely into a tabular format.
Examples: JSON files, XML files, and NoSQL databases.
Usage: Often used in web scraping, API responses, and social media analysis
Based on Representation
Numerical Data: Features measured in numbers (e.g., age, income).
Categorical Data: Represents Categories or labels (e.g., gender, fruit type).
Ordinal Data: Categorical data with an essential order (e.g., clothing sizes: Small, Medium, Large).
Based on Labeling
Labeled Data: Includes input variables and corresponding target outputs. Example: Features like "age" and "income" with a label like "loan approval status."
Unlabeled Data: Contains only input variables without any target labels. Example: Images without annotations.
From Data to Knowledge
Data: Data is raw, unprocessed facts, values, text, sounds or images that have not been interpreted or analyzed. Without data, training models and driving modern research or automation would be impossible.
Information: As data gets processed, interpreted and organized, it turn into information. It gives users meaningful insights which can be understood easily and utilized.
Knowledge: Knowledge is the product of combining experience, learning, Information and insights. It allows individuals or businesses to construct awareness, create ideas and make well-informed decisions.
A store collects customer feedback (raw data). Analyzing this data for common themes (e.g., product quality, pricing) creates information. Applying these insights to improve product offerings results in knowledge.
Real-World Examples of ML Data
Domain
Data Example
Healthcare
Patient records, lab results, imaging
Finance
Transaction logs, credit history
E-commerce
User reviews, purchase history
Transportation
GPS data, traffic reports
Social Media
Text, images, user engagement metrics
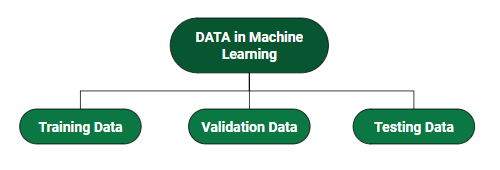
How do we split data in Machine Learning?
Effective ML model development involves splitting data into different sets:
Helps fine-tune the model by evaluating it during training.
Useful for hyperparameter tuning and early stopping.
3. Testing Data
Used after training is complete.
Evaluates how well the model generalizes to unseen data
In machine learning, data is king. Algorithms and models may be the engines, but data is the fuel. A deep understanding of data—not just its structure, but also how to prepare and use it effectively—sets the foundation for building powerful, reliable, and ethical machine learning systems.
Facts About the Growing World of Data
The value of data can be demonstrated with actual-world statistics:
Massive Growth: From 2005 to 2020, data generation increased 300x to 40 zettabytes.
Medical Boom: The medical sector generated 161 billion GB of data in 2011 alone.
Social Media Surge: 200 million users send 400 million tweets every day.
Streaming Era: More than 4 billion hours of video are viewed in a month.
Content Flood: Users post approximately 30 billion items of content per month.
Data Reliability Problems: Close to 27% of organizational data is not correct, creating distrust in decision-making.
Advantages of Using Data in Machine Learning
Improved accuracy: Machine learning algorithms can detect more intricate connections between inputs and outputs when given large amounts of data, which improves prediction and classification accuracy.
Automation: Compared to humans, machine learning models can complete repetitive tasks more quickly and accurately while also automating decision-making processes.
Personalization: By using data to tailor experiences for individual users, machine learning algorithms can increase user.
Cost savings: Businesses can save costs using automation with machine learning by minimizing the effort required by humans and maximizing efficiency.
Challenges in Using Data for Machine Learning
Data Quality: Incomplete, noisy, or irrelevant data can lead to poor model performance.
Data Quantity: Insufficient data limits the model’s ability to generalize.
Bias and Fairness: Datasets with bias can reinforce discrimination and unjust results.
Overfitting: Model memorizes training data but does not perform on novel inputs.
Underfitting: Model too simple and unable to identify patterns.
Concerns Regarding Privacy: Sensitive information, when exploited, may result in violations of privacy and legal problems.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}