Monte Carlo Tree Search (MCTS) in Machine Learning
Last Updated : 11 May, 2026
Monte Carlo Tree Search (MCTS) is a method used for problems with very large decision spaces, such as game Go, which has around 10170 possible states. It builds a search tree step-by-step using random simulations to choose better moves.
Avoids exploring every possible move.
Balances trying new moves (exploration) and using good known moves (exploitation).
Uses statistical sampling to guide decisions.
Works well when the search space is too large to evaluate fully.
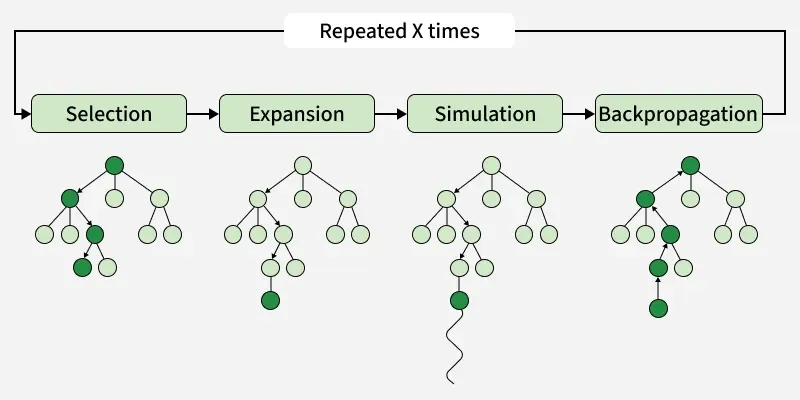
1. Selection : Starting at the root node, MCTS moves down the tree using a selection rule. The most common rule is UCT (Upper Confidence Bounds for Trees), which balances:
Exploitation: choosing moves with higher average reward
Exploration: trying moves with less information
2. Expansion : When the selection phase reaches a leaf node that isn't terminal, the algorithm expands the tree by adding one or more child nodes representing possible actions from that state.
3. Simulation Phase: From the newly added node, a random playout is performed until reaching a terminal state. During this phase, moves are chosen randomly or using simple heuristics, making the simulation computationally inexpensive.
4. Backpropagation Phase: The result of the simulation is propagated back up the tree to the root, updating statistics (visit counts and win rates) for all nodes visited during the selection phase.
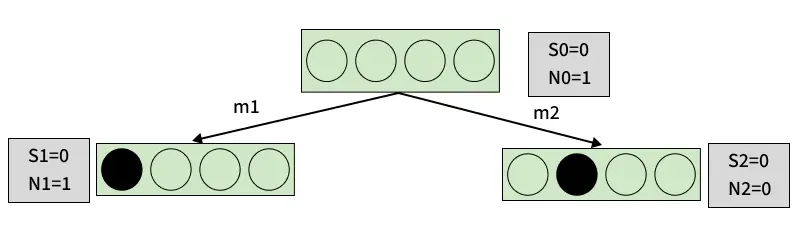
Mathematical Foundation: UCB1 Formula
The selection phase relies on the UCB1 (Upper Confidence Bound) formula to determine which child node to visit next:
Where:
is the average reward of node i
is the exploration parameter (typically √2)
is the total number of visits to the parent node
is the number of visits to node
The first part encourages exploitation, while the second drives exploration. The logarithm ensures exploration reduces as data increases.
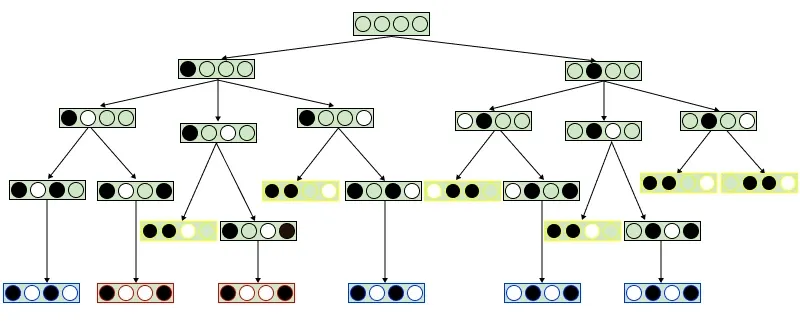
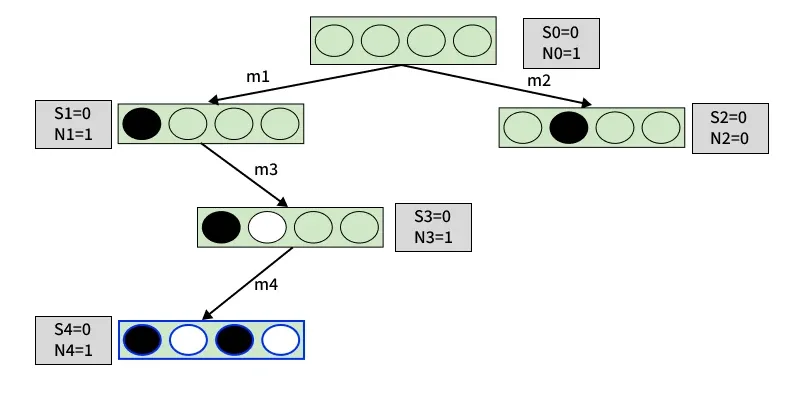
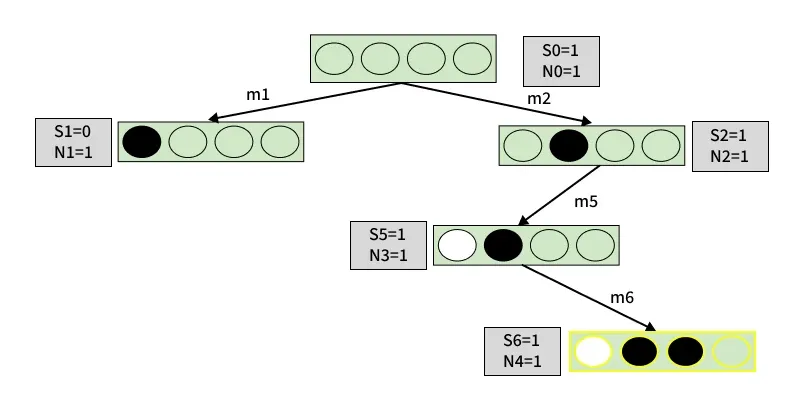
Monte Carlo Tree Search Example
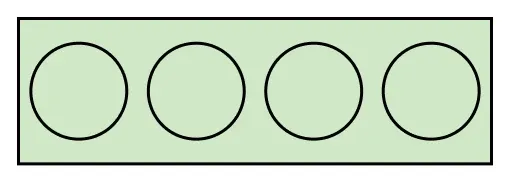
Game: Pair
Players: 2
Board: 4 boxes
Winning Condition: A player wins by marking any two adjacent boxes.
With enough iterations, MCTS plays strong and avoids losing lines. Increasing simulation count improves decision quality. A real-world example is AlphaGo, which combined MCTS with neural networks and achieved world-class performance by running millions of simulations per move.
Practical Applications Beyond Games
Planning and Scheduling: The algorithm can optimize resource allocation and task scheduling in complex systems where traditional optimization methods struggle.
Neural Architecture Search: MCTS guides the exploration of neural network architectures, helping to discover optimal designs for specific tasks.
Portfolio Management: Financial applications use MCTS for portfolio optimization under uncertainty, where the algorithm balances risk and return through simulated market scenarios.
Advantages
No domain knowledge needed: MCTS only needs valid moves and end conditions.
Balances exploration and exploitation: Uses UCB to pick promising and less-explored moves.
Anytime algorithm: Can stop at any moment and still return the best estimated move.
Works well with large search spaces: Focuses on useful parts of the tree instead of exploring everything.
Asymmetric tree growth: Spends more time on good branches, improving decision quality efficiently.
Limitations
Simulation-heavy: needs many rollouts for consistent results
High variance: random rollouts can lead to noisy estimates
Tactical blindness: may miss short forced sequences

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}