 |
VOOZH | about |
|
VOOZH | about |
Prerequisites: OPTICS Clustering This article will demonstrate how to implement OPTICS Clustering technique using Sklearn in Python. The dataset used for the demonstration is the Mall Customer Segmentation Data which can be downloaded from Kaggle.
Step 1: Importing the required libraries
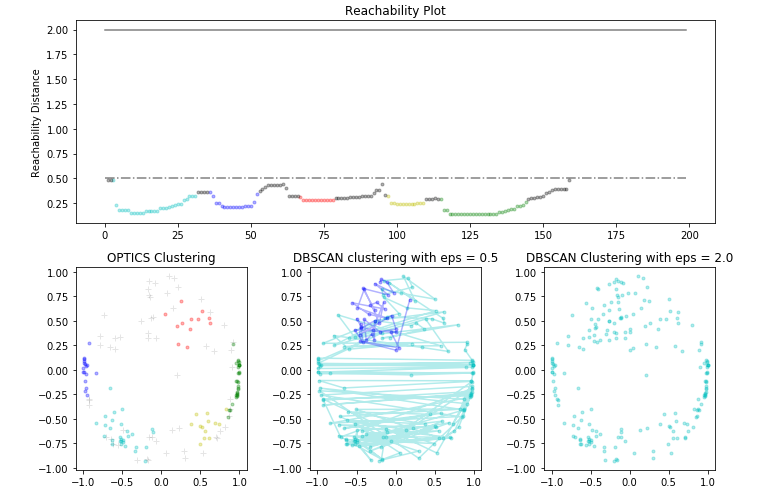
OPTICS (Ordering Points To Identify the Clustering Structure) is a density-based clustering algorithm that is used to identify the structure of clusters in high-dimensional data. It is similar to DBSCAN, but it also produces a cluster ordering that can be used to identify the density-based clusters at multiple levels of granularity.
The implementation of OPTICS clustering using scikit-learn (sklearn) is straightforward. You can use the OPTICS class from the sklearn.cluster module. Here is an example of how to use it:
In this example, the min_samples parameter controls the minimum number of samples required to form a dense region, the xi parameter controls the maximum distance between two samples to be considered as a neighborhood, and the min_cluster_size parameter controls the minimum size of a dense region to be considered as a cluster.
The fit method is used to fit the model to the data, and the labels_ attribute is used to get the cluster labels for each sample in the data.
Note that the implementation of OPTICS clustering in scikit-learn is based on the original paper by Ankerst, Mihael, and Markus (1999). You might consider reading this paper to learn more about the algorithm.
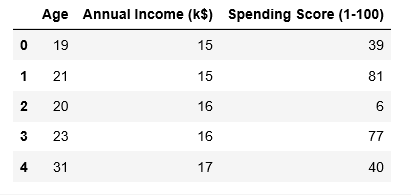
Step 2: Loading the Data
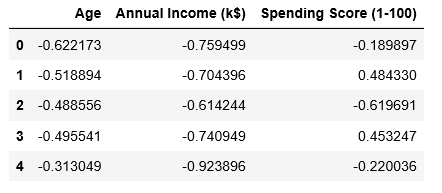
Step 3: Preprocessing the Data
Step 4: Building the Clustering Model
Step 5: Storing the results of the training
Step 6: Visualizing the results
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}