 |
VOOZH | about |
|
VOOZH | about |
Machine Learning Operations (MLOps) is the union of Data Engineering, Machine Learning, and DevOps. It aims to standardize the lifecycle of ML products, moving them from isolated "notebook experiments" to reliable, scalable production services.
While traditional software is primarily logic-driven, ML is data-driven. This creates unique hurdles:
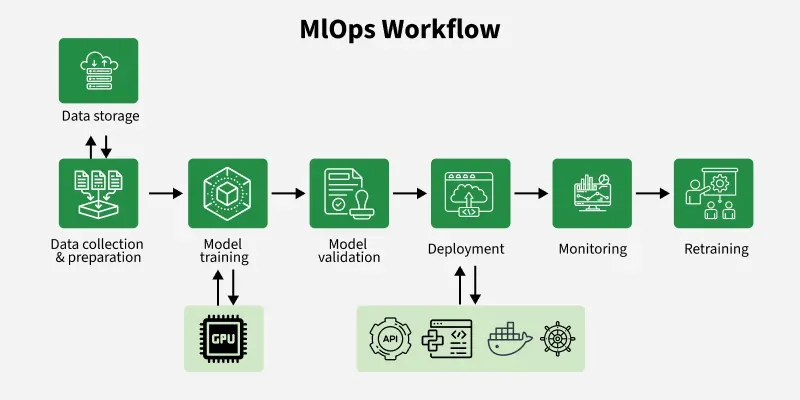
MLOps workflow helps teams to manage machine learning projects smoothly and automatically. Here's how it works:
To implement MLOps effectively, organizations usually progress through three levels of automation:
| Level | Name | Description |
|---|---|---|
| Level 0 | Manual Process | Data scientists build and deploy models manually. Script-driven, no automation, high risk of failure. |
| Level 1 | ML Pipeline Automation | The entire training pipeline is automated. Whenever new data arrives, the model is retrained and validated automatically. |
| Level 2 | CI/CD Pipeline Automation | Full "Continuous Delivery." Not just the model, but the pipeline code is automatically tested and deployed. |
| Feature | DevOps | MLOps |
|---|---|---|
| Core Purpose | Focuses on automating the development and deployment of traditional software. | Extends DevOps principles to machine learning systems, managing not only code but also data and models. |
| Main Assets Managed | Handles code, application binaries and infrastructure. | Handles code plus datasets, features, model versions and experiments. |
| Lifecycle Coverage | Covers coding → testing → deployment → monitoring. | Adds stages like data preparation, feature engineering, model training, validation, deployment, retraining and drift management. |
| Nature of Updates | Updates happen when developers push new features or bug fixes. | Updates are triggered not only by new features but also by changing data, shifting patterns or model performance drops. |
| Complexity | Mostly predictable, since software code is static once shipped. | Dynamic and complex, because data evolves, models decay and retraining is often required. |
| Monitoring Needs | Monitors system uptime, response times, errors and stability. | Monitors model accuracy, fairness, bias, drift in data, latency of predictions and compliance with regulations. |
| Tools Used | Jenkins, Git, Docker, Kubernetes, Terraform, Ansible. | Adds ML-specific tools like MLflow, Kubeflow, TensorFlow Extended (TFX), DVC, Weights & Biases and feature stores. |
| Teams Involved | Software developers and operations engineers. | Includes data scientists, ML engineers, DevOps and domain experts working together. |
{kind=link}
{kind=link}