Decision Tree models are capable of learning very detailed decision rules but this often causes them to fit too closely to the training data. As a result, their accuracy drops significantly when evaluated on new, unseen samples.
Complexity: Decision trees become overly complex, fitting training data perfectly but struggling to generalize to new data.
Memorizing Noise: It can focus too much on specific data points or noise in the training data, hindering generalization.
Overly Specific Rules: Might create rules that are too specific to the training data, leading to poor performance on new data.
Feature Importance Bias: Certain features may be given too much importance by decision trees, even if they are irrelevant, contributing to overfitting.
Sample Bias: If the training dataset is not representative, decision trees may overfit to the training data's idiosyncrasies, resulting in poor generalization.
Lack of Early Stopping: Without proper stopping rules, decision trees may grow excessively, perfectly fitting the training data but failing to generalize well.
Strategies to Overcome Overfitting
Some of the strategies to prevent overfitting in decision trees are:
Limit Tree Depth: Restricts how deep the tree can grow, preventing unnecessary branches.
Minimum Samples per Split: Ensures splits occur only when enough samples are available.
Minimum Samples per Leaf: Creates larger, more stable leaf nodes.
Feature Selection: Removes irrelevant features that encourage noisy splits.
Pruning: Reduces model complexity by trimming weak branches.
Regularization: Introduces penalty controls to discourage complex structures.
Cross-Validation: Helps detect unstable decisions across data folds.
Hyperparameters to Reduce Overfitting
Some of the hyperparameters used to minimize overfitting are:
max_depth: Limits how deep the tree can grow.
min_samples_split: Requires more samples before splitting.
min_samples_leaf: Ensures leaves have enough data.
max_leaf_nodes: Restricts total leaf node count.
max_features: Reduces feature consideration per split.
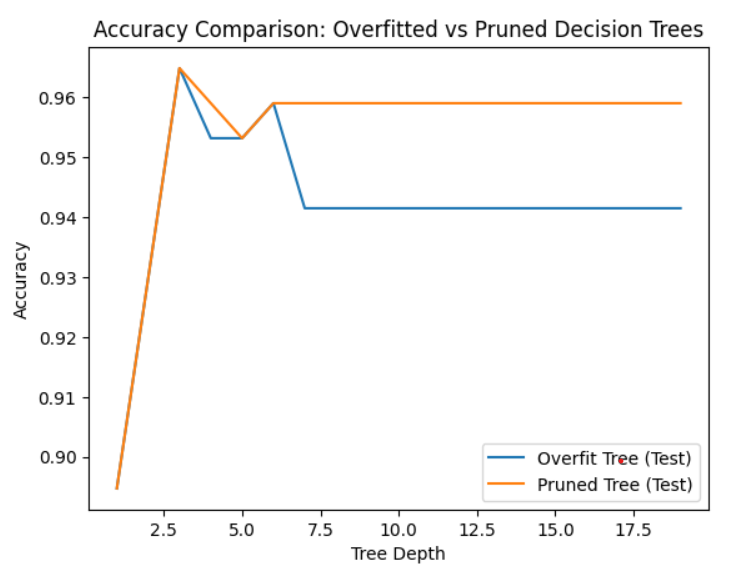
Implementation of Pruning
Implementing pruning to handle overfitting in decision tree.
Step 1: Install Required Libraries
Installing Scikit-Learn and Matplotlib for model creation, dataset loading, splitting and plotting accuracies.
Step 2: Import Modules
Importing required modules.
DecisionTreeClassifier: Build decision tree models

{kind=link}
{kind=link}
{kind=link}