Precision and recall are two evaluation metric used to check the performance of Machine Learning Model.Precision is the ratio of a model’s classification of all positive classifications as positive. Recall tells us how many of the actual positive items the model was able to find. Precision and recall helps in classification problems.
1. Precision
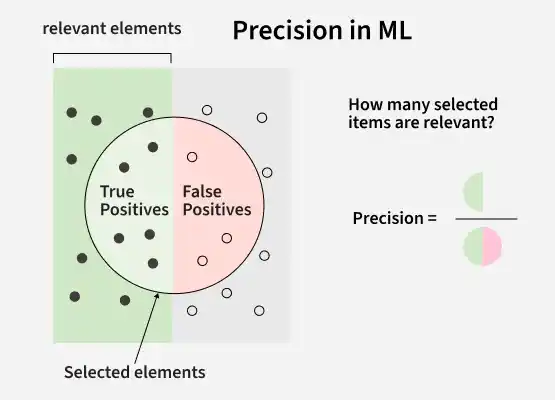
Precision is the ratio between the True Positives and all the Positives. It shows how many of the “yes” predictions made by the model were actually correct. It helps us reduce wrong “yes” guesses which are called false positives (FP). Precision is calculated as:
Precision helps us understand how accurate a model's “yes” predictions are. It is especially useful when the data has more of one kind of result than the other.
For example if most emails are not spam and only a few are then precision helps us see how well the model is finding the spam without making too many mistakes. In such uneven data precision helps measure how correctly the model is picking out the less common group like spam or fraud.
Advantages of High Precision
A model with high precision is very good at avoiding mistakes when it says “yes.” This is important in situations where false alarms are a big problem. For example:
In spam email detection it's better if real emails don't get wrongly marked as spam.
We care more about getting the important emails right than stopping every single spam message.
So in these cases a model that gives fewer wrong "yes" answers is more useful.
Limitations of Precision
If we only care about precision then model may miss some real cases. It becomes too careful and may say “no” even when something is actually “yes.”
If the model is too focused on being precise it might let lots of spam emails into your inbox because it's afraid of wrongly marking a real email as spam.
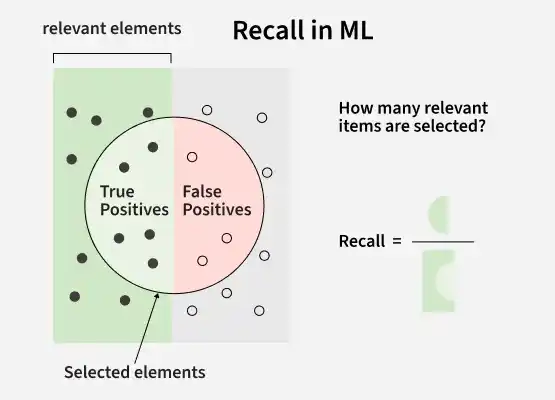
2. Recall
Recall tells us how well a model finds all the correct “yes” cases in the data. It checks how many real positive cases the model was able to correctly identify. The formula to calculate recall is:

{kind=link}
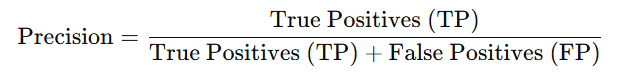{kind=link}
{kind=link}
{kind=link}
{kind=link}