 |
VOOZH | about |
|
VOOZH | about |
Random Forest hyperparameter tuning involves optimizing model parameters to improve performance and accuracy. By adjusting settings like the number of trees, depth and feature selection, it is possible to build a more efficient and well‑generalized machine learning model.
Since we are talking about Random Forest Hyperparameters, let us see what different Hyperparameters can be tuned:
1. n_estimators: It defines the number of trees in the forest. More trees typically improve model performance but increase computational cost. In the below example it takes 100 trees.
By default: n_estimators=100
2. max_features: Limits the number of features to consider when splitting a node. This helps control overfitting.
By default: max_features="sqrt" [available: ("sqrt", "log2", None)
3. max_depth: Controls the maximum depth of each tree. A shallow tree may underfit while a deep tree may overfit. So choosing right value of it is important.
By default: max_depth=None
4. max_leaf_nodes: Limits the number of leaf nodes in the tree hence controlling its size and complexity. None means it takes an unlimited number of nodes.
By default: max_leaf_nodes = None
5. max_samples: Apart from the features, we have a large set of training datasets. max_sample determines how much of the dataset is given to each individual tree. None means data.shape[0] is taken.
By default: max_samples = None
6. min_samples_split: Specifies the minimum number of samples required to split an internal node. In the below example every node has 2 subnodes.
By default: min_samples_split = 2
Scikit-learn offers tools for hyperparameter tuning which can help improve the performance of machine learning models. Hyperparameter tuning involves selecting the best set of parameters for a given model to maximize its efficiency and accuracy. We will explore two commonly used techniques for hyperparameter tuning: GridSearchCV and RandomizedSearchCV.
Both methods are essential for automating the process of fine-tuning machine learning models and we will examine how each works and when to use them. Below is the code with random forest working on heart disease prediction.
Download the dataset fromhere.
Output:
The classification report shows that the model has an accuracy of 84% with good precision for class 1 (0.90) but slightly lower precision for class 0 (0.77) and a recall of 0.87 for class 0. This suggests that fine-tuning hyperparameters such as n_estimators and max_depth could help improve the performance especially for class 0.
First let's use GridSearchCV to obtain the best parameters for the model. It is a hyperparameter tuning method in Scikit-learn that exhaustively searches through all possible combinations of parameters provided in the param_grid. For that we will pass RandomForestClassifier() instance to the model and then fit the GridSearchCV using the training data to find the best parameters.
Output:
Updating the Model
Now we will update the parameters of the model by those which are obtained by using GridSearchCV.
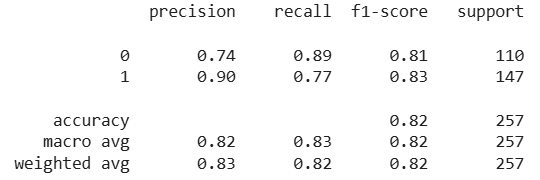
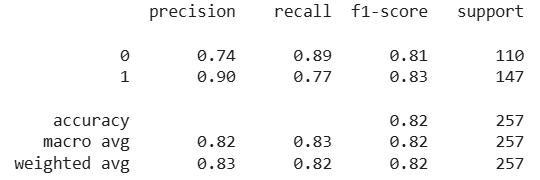
Output:
RandomizedSearchCV performs a random search over a specified parameter grid. It randomly selects combinations and evaluates the model often leading to faster results especially when there are many hyperparameters.
Now let's use RandomizedSearchCV to obtain the best parameters for the model. For that we will pass RandomForestClassifier() instance to the model and then fit the RandomizedSearchCV using the training data to find the best parameters.
Output:
RandomForestClassifier(max_depth=3, max_features='log2', max_leaf_nodes=6)
Updating the model
Now we will update the parameters of the model by those which are obtained by using RandomizedSearchCV.
Output:
Both methods help identify the best combination of hyperparameters leading to improved model accuracy and more balanced precision, recall and F1-scores for both classes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}