 |
VOOZH | about |
|
VOOZH | about |
Principal Component Analysis (PCA) is a powerful technique used in data science for dimensionality reduction, feature extraction, and data visualization. One of the key outputs of PCA is the explained_variance_ratio_, which indicates the proportion of the dataset's variance that each principal component accounts for. However, understanding which original features contribute to these principal components can be crucial for interpreting the results. This article will guide you through the process of recovering feature names associated with the explained_variance_ratio_ in PCA using Scikit-Learn.
Table of Content
PCA is an unsupervised learning algorithm that transforms the original features into a new set of features called principal components. These components are orthogonal to each other and are ordered by the amount of variance they explain in the data. The primary goals of PCA include:
Explained variance ratio is a measure of the percentage of the total variance in a given dataset for each principal component. The explained variance ratio of a principal component is measured as the ratio of its eigenvalue to the sum of the eigenvalues of all the principal components.
Using the explained_variance_ratio attribute (from Sklearn PCA), one can access the explained variance ratio for each principal component. The code is as follows:
The steps for the above code as follows:
Output:
PC1: 0.31
PC2: 0.15
PC3: 0.11
PC4: 0.09
PC5: 0.09
Let's create a visualisation plot for explained variance ratio for each principal component.
Output:
The above code plots the chart of variance proportions for each principal components. This is useful especially when trying to identify how much variation is explained by each of the principal components as well as when seeking to visualize the components within the data samples.
PCA is an orthogonal linear transformation that transforms the data into a new coordinate system. So, the features retrieved from PCA are not the original features. Information about the original feature is available in the pca attribute: components. To understand which original features contribute to the principal components, we need to examine the pca.components_ attribute.
Let's follow the below steps to recover feature names.
First of all, to balance them, you need to fit a PCA model to your data.
After applying PCA to the given data and finding the values of the first few principal components, it is possible to get the component weights which give the information about contribution of each original feature to the principal components.
Output:
Component Weights:
[[ 0.57735027 0.57735027 0.57735027]
[-0.81649658 0.40824829 0.40824829]]
Construct a list where each element is a mapping of the initial feature name and its corresponding weight for each of the principal components.
They should show the name of each feature and its corresponding weight meaning how much it contributes to each of the principal component.
Output:
Feature names contributing to Component 1:
Feature1: 0.577350269189626
Feature2: 0.5773502691896255
Feature3: 0.5773502691896255
Feature names contributing to Component 2:
Feature1: -0.8164965809277258
Feature2: 0.40824829046386313
Feature3: 0.40824829046386313
Here's an example code snippet demonstrating how to recover feature names after performing PCA using scikit-learn. Here we make use of iris dataset. It consists of 3 different types of irises (Setosa, Versicolour, and Virginica) and has 4 features: sepal length, sepal width, petal length, and petal width. The code is as follows:
Output:
Feature names contributing to Principal Components:
Component 1: [('petal length (cm)', 0.8566706059498349), ('sepal length (cm)', 0.36138659178536864), ('petal width (cm)', 0.3582891971515507), ('sepal width (cm)', -0.08452251406456868)]
Component 2: [('sepal width (cm)', 0.7301614347850266), ('sepal length (cm)', 0.6565887712868423), ('petal length (cm)', -0.17337266279585706), ('petal width (cm)', -0.07548101991746337)]
Component 3: [('sepal width (cm)', 0.5979108301000855), ('sepal length (cm)', -0.5820298513060651), ('petal width (cm)', 0.5458314320200757), ('petal length (cm)', 0.0762360758209632)]
In the above code, n_components is set to 3. Hence, PCA will create 3 new features that are a linear combination of the 4 original features. Following the PCA data analysis and fitting the model, the next step is to get hold of the component weights by using the command: pca.components_. Finally, for each principal components, we generate the mapping that assigns names to the matrix columns and weights to the features. Last for all, we want to know the features associated to the principal components so we print them out.
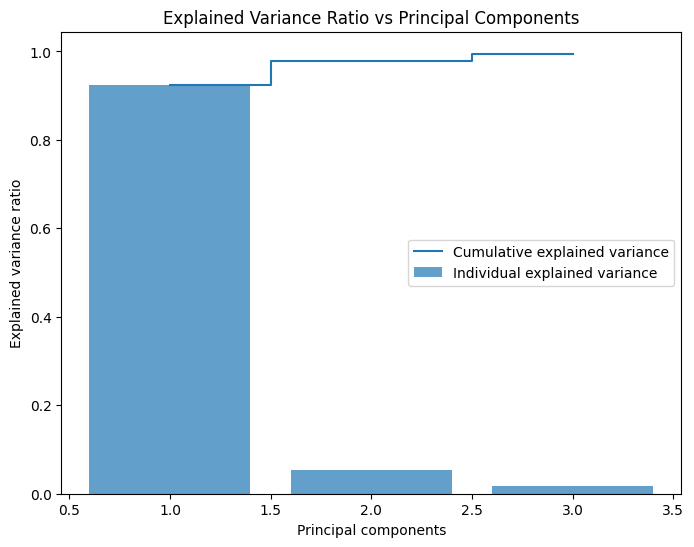
Let's plot the explained variance ratio and cumulative explained variance for each principal component.
Output:
Here we get the explained variance ratio from the pca object using the explained_variance_ratio attribute and calculate the cumulative sum of the explained variance ratio using the cumsum() method provided by Numpy. Finally, we plot the explained variance ratio and cumulative explained variance ratio for each principal component using Matplotlib.
Understanding the feature contributions to principal components can be useful in various scenarios:
Recovering the feature names associated with the explained_variance_ratio_ in PCA is a crucial step in interpreting the results of PCA. By examining the pca.components_ attribute, we can understand the contribution of each original feature to the principal components. This process enhances our ability to make informed decisions based on the PCA results.
{kind=link}
{kind=link}
{kind=link}