 |
VOOZH | about |
|
VOOZH | about |
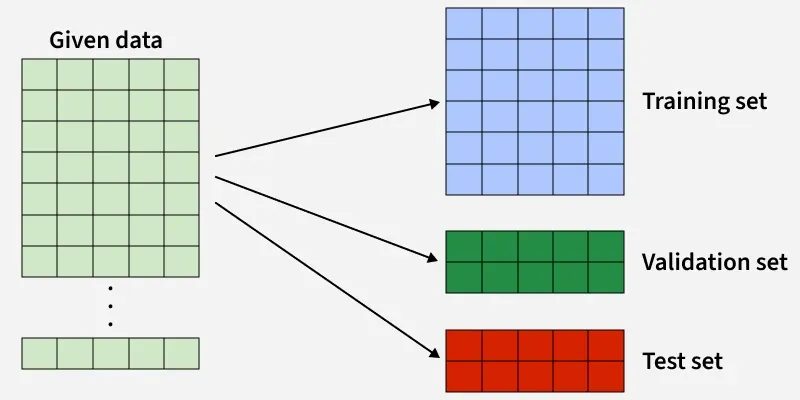
Training, validation and testing sets are three essential components in building reliable machine learning models. The training set teaches the model patterns, the validation set helps fine‑tune hyperparameters and prevent overfitting and the testing set evaluates how well the model performs on completely unseen data.
The training set is the portion of the dataset used to fit the machine learning model. During training, the algorithm learns patterns, relationships and parameters (such as weights in neural networks or coefficients in regression models) directly from this data. The model repeatedly adjusts itself to minimize the training error using optimization techniques like gradient descent.
Example:
Output:
The validation set is a separate subset of data used to tune model hyperparameters and make design decisions during training. Unlike the training set, it is not used to update model weights directly. Instead, it provides an unbiased estimate of model performance during development.
Example:
Output:
Validation Accuracy: 0.8010204081632653
The testing set is a completely independent subset used to evaluate the final model’s performance after all training and tuning are complete. It simulates how the model will perform on unseen, real-world data and provides the most reliable estimate of generalization.
Example:
Output:
Test Accuracy: 0.817258883248731
Let's compare them:
| Aspect | Training Set | Validation Set | Testing Set |
|---|---|---|---|
| Core Objective | Learn patterns and fit model parameters | Tune hyperparameters and select the best model | Evaluate final model performance |
| Role in Learning | Directly involved in model learning | Indirect role (guides learning decisions) | No role in learning |
| Parameter Updates | Model weights are updated repeatedly | Weights remain unchanged | Weights remain unchanged |
| Hyperparameter Influence | Does not guide hyperparameter selection | Actively used for hyperparameter tuning | Must not influence hyperparameters |
| Typical Usage Frequency | Used many times across epochs/iterations | Used multiple times during experimentation | Ideally used only once |
| Performance Interpretation | Indicates how well the model fits seen data | Indicates whether the model is overfitting or underfitting | Indicates real-world generalization |
| Risk if Overused | Severe overfitting to training data | Validation leakage and biased tuning | Inflated and unreliable performance estimates |
| Relationship to Deployment | Indirect, supports model creation | Indirect, supports model refinement | Direct indicator of deployment readiness |
| Typical Dataset Proportion | Largest portion of the dataset | Medium-sized portion | Smallest portion |
{kind=link}
{kind=link}
{kind=link}