Web mining is the process of applying data-mining, machine-learning and analytical techniques to extract meaningful patterns and insights from the vast data available on the World Wide Web. It aims to discover useful knowledge from web content, structure and user interactions. Its core objective is to convert raw, unstructured web data into actionable information.
Handles diverse data types including text, images, multimedia, hyperlinks and server logs.
Combines concepts from data mining, NLP, information retrieval and AI.
Helps understand user behaviour, website performance and underlying patterns within web ecosystems.
Works with unstructured, semi-structured and massive, rapidly updating online data.
Categories
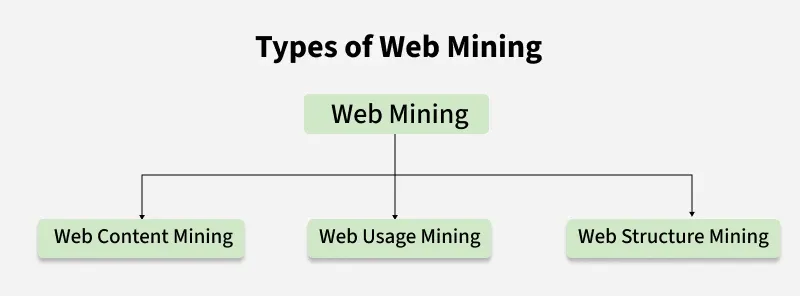
Web mining is broadly classified into three categories based on the type of data being analyzed and the techniques used for analysis,
Web Content Mining focuses on extracting useful information from the actual contents of web pages, including text, images, audio, video and metadata. It deals with unstructured or semi-structured data and transforms it into structured forms for analysis.
Uses NLP, text mining, multimedia analysis, classification and clustering.
Identifies keywords, topics, themes and patterns in documents and media.
Helps improve search relevance, content organization and information retrieval.
2. Web Structure Mining
Web Structure Mining analyzes the link structure of the web to identify relationships between pages and understand how information is connected. It treats the web as a directed graph where pages are nodes and hyperlinks are edges.
Helps identify authoritative or influential pages (e.g., PageRank).
Reveals communities, clusters and navigation paths within sites.
Useful for SEO, ranking, website design and detecting related content groups.
3. Web Usage Mining
Web Usage Mining deals with analyzing user behaviour by mining web server logs, clickstreams, cookies and session data. It discovers how users navigate, what they prefer and what patterns emerge from usage activity.
Uses log preprocessing, session reconstruction, pattern mining, clustering and association rules.
Enables personalization, recommendations, adaptive websites and fraud detection.
Helps businesses study user journeys, optimize conversions and improve UX.
Process
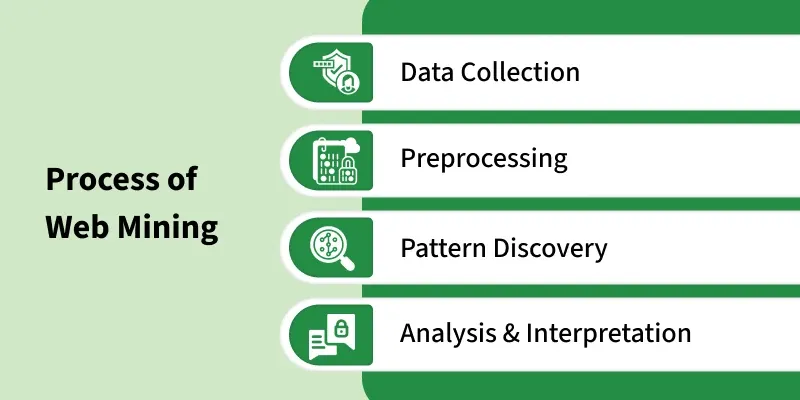
The process of web mining typically involves the following steps:
Data Collection: Collection of raw data from web pages, logs, clickstreams, metadata, multimedia and hyperlinks.
Preprocessing: Removing noise, parsing HTML, handling missing values, session identification and converting data into analyzable formats.
Pattern Discovery: Applying machine-learning and data-mining techniques such as clustering, classification, NLP, association rules or sequential pattern mining.
Analysis & Interpretation: Interpreting discovered patterns for decision-making in areas like personalization, design optimization, marketing or security.
Web Mining vs. Data Mining
Let's see the major differences between data mining and web mining:
Parameter
Data Mining
Web Mining
Definition
Extracts patterns and knowledge from large, structured datasets.
Applies data-mining techniques to web data (content, structure, logs) for knowledge extraction.
Nature of Data
Mostly structured (tables, records).
Semi-structured or unstructured (HTML, media, logs).

{kind=link}
{kind=link}
{kind=link}