 |
VOOZH | about |
|
VOOZH | about |
Support Vector Machines (SVMs) are powerful machine learning algorithms used for classification and regression tasks. When dealing with linearly separable data, SVMs use a linear kernel to find the optimal hyperplane that separates the classes. A crucial parameter in this process is C, which plays a significant role in shaping the decision boundary.
The parameter C in Support Vector Machines (SVMs) with a linear kernel controls the trade-off between the margin of the decision boundary and the accuracy of classifying the training data. Essentially, C determines how much the SVM should penalize misclassifications, influencing the complexity and accuracy of the model.
A higher C value makes the model aim for fewer misclassifications by using a smaller margin, while a lower C allows more misclassifications with a wider margin.
The parameter C is a regularization parameter that balances two competing goals:
Now, this is what c values convey:
C means that the SVM will be heavily penalized for any misclassifications. This leads to a narrower margin, as the model will try to classify all training points correctly, even if it results in a more complex decision boundary. In practice, this can lead to overfitting, where the model performs well on the training data but poorly on new, unseen data.C means that the SVM will be less penalized for misclassifications. This results in a wider margin, leading to a simpler decision boundary. While this can reduce overfitting, it may also reduce the training accuracy, as some points may be misclassified to achieve a larger margin.Example:
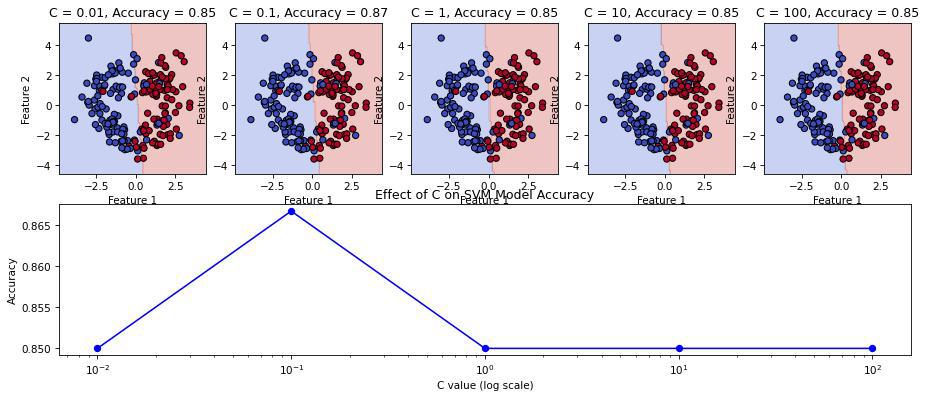
This code demonstrates how varying the C value in an SVM model with an linear kernel affects decision boundaries and model accuracy. We generate synthetic data, train the model with different C values, and plot both the decision boundaries for each C and the corresponding accuracy on a log-scale graph. Lower C values result in smoother boundaries, favoring generalization, while higher C values create tighter boundaries, which may overfit.
Output:
As C increases (1, 10, and 100), the decision boundary becomes increasingly non-linear, with more bends and curves. This suggests that the SVM is attempting to fit the training data more precisely, even at the risk of overfitting. When C is small (0.01 and 0.1), the decision boundary is linear, indicating that the SVM is not trying to capture complex patterns in the data.
The accuracy of the model appears to be relatively stable across different values of C. The optimal value of C depends on the specific dataset and the desired trade-off between model complexity and accuracy. Cross-validation is a common technique to find the best C value by evaluating the model's performance on a validation set.
{kind=link}
{kind=link}