 |
VOOZH | about |
|
VOOZH | about |
The K-Nearest Neighbors (KNN) algorithm is known as a lazy learnerbecause it does not build an internal model during the training phase. Instead, it simply stores the entire training dataset and defers any processing until it needs to make a prediction. Here’s how K-NN works:
Lazy learning algorithms like K-NN are useful when the data is noisy or has a complex structure. However, K-NN can be slow for large datasets because it has to search through all the data points each time it makes a prediction. Unlike eager learning algorithms, which build a model during training, lazy learning algorithms simply store the data, making their training phase extremely quick since no processing or learning happens at that stage.
To summarize : The KNN algorithm classifies new data by comparing it to the stored training data without building a model, making it simple but potentially slow for large datasets.
KNN operates based on the principle of similarity. When given a new data point to classify or predict, KNN looks at its nearest neighbors in the training dataset and assigns a label based on those neighbors' labels. The algorithm uses a distance metric (such as Euclidean distance) to determine which points are closest to the new input. Here’s how it works:
When you provide training data to a KNN algorithm, it does not perform any training or model construction. It simply stores the entire training dataset in memory.
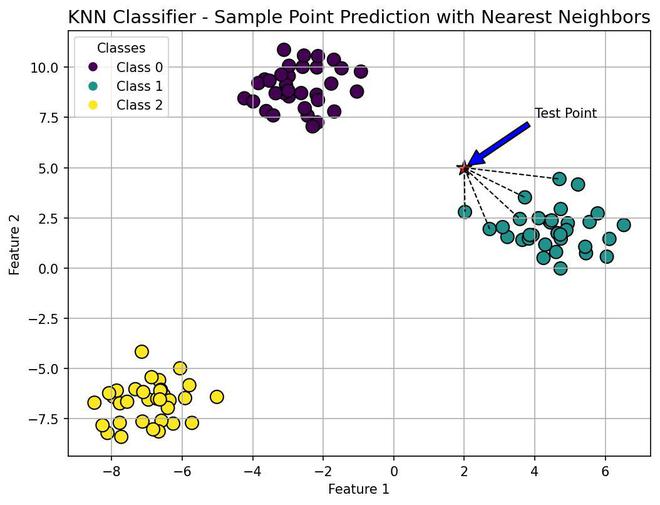
Prediction Phase: When a new data point is presented for classification, the KNN algorithm springs into action. It calculates the distance between the new data point and all the stored training data points. The algorithm then identifies the K nearest neighbors (hence the name KNN) and uses their class labels to determine the class of the new data point. For example, if K is set to 5, the algorithm will look at the 5 closest neighbors and classify the new data point based on the majority class among these neighbors.
KNN is called lazy because it doesn't involve any training phase where a model is built using the training data. Instead of learning patterns or relationships from the data upfront (as eager learners do), KNN simply memorizes all of the training examples and waits until it receives a query to perform any calculations.This lazy behavior has several consequences:
Despite its limitations, KNN is a valuable algorithm in certain scenarios. It is particularly useful for clustering unlabeled data, detecting anomalies, and classifying data points into existing labels. KNN is also well-suited for online learning because it can easily update the stored data when new samples arrive, without the need for retraining the entire model. However, for applications that require real-time predictions, such as facial recognition or speech recognition, eager learning algorithms are generally more suitable due to their faster prediction times.
{kind=link}
{kind=link}