Word Sense Disambiguation in Natural Language Processing
Last Updated : 5 Aug, 2025
Word Sense Disambiguation (WSD) is the process of determining which meaning of a word is intended in a particular context. It addresses the challenge of polysemy, where many words have multiple related meanings. For example, when we encounter the sentence "I went to the bank," we automatically understand whether "bank" refers to a financial institution or the edge of a river based on surrounding context clues.
WSD is important in many natural language processing (NLP) applications because if word meanings are misidentified, the results can be problematic:
Machine translation systems may produce incorrect translations due to misinterpretation of word meanings.
Information retrieval systems might return irrelevant results because of semantic uncertainty or confusion.
Question-answering systems require precise word meanings to provide accurate and relevant answers.
Primary Approaches to Word Sense Disambiguation
WSD techniques can be categorized into three main approaches, each with distinct methodologies and use cases.
1. Knowledge-Based Methods
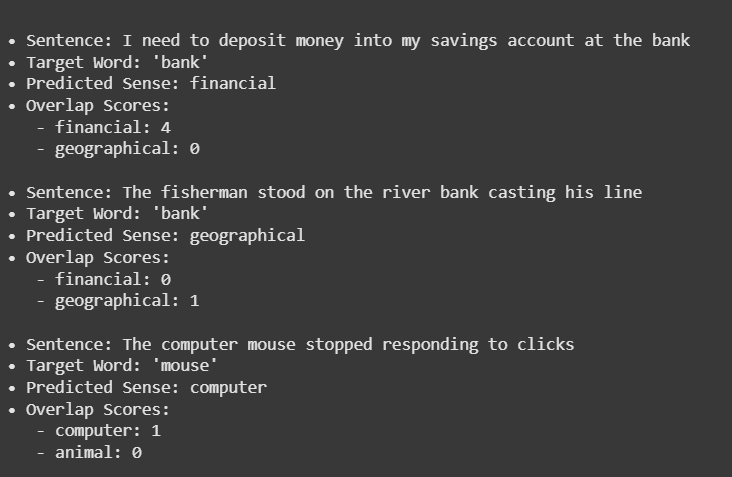
Knowledge-based approaches utilize lexical resources such as dictionaries and semantic networks to determine word meanings. The Lesk algorithm works over this approach.
Compare context words with dictionary definitions of candidate senses
Calculate overlap between contextual words and definitional content
Select the sense with maximum overlap score
Advantages:
Does not require annotated training data
Leverages existing linguistic knowledge bases
Provides interpretable disambiguation decisions
The Lesk algorithm assumes that words used together in coherent text will have semantic relationships reflected in their dictionary definitions.
2. Supervised Learning Methods
Supervised approaches treat WSD as a classification problem, training machine learning models on datasets where word instances have been manually annotated with correct senses.
Key characteristics:
Requires substantial amounts of sense-annotated training data
Employs standard machine learning algorithms such as support vector machines, decision trees or neural networks
Uses contextual features including surrounding words and syntactic relationships
Training process:
Extract features from annotated examples
Train classifier to map feature vectors to sense labels
Apply trained model to disambiguate new instances
While supervised methods achieve high accuracy, they face the challenge of obtaining sufficient annotated data for all word-sense combinations.
3. Unsupervised Learning Methods
Unsupervised approaches operate without sense-labeled training data, instead relying on distributional patterns in large text corpora.
Fundamental principle:
Words appearing in similar contexts tend to have similar meanings
Cluster word occurrences based on contextual similarity
Assign sense labels to resulting clusters
Modern techniques:
Utilize word embeddings and contextualized representations
Employ clustering algorithms to group similar contexts
Leverage large-scale language models for contextual understanding
These methods are particularly valuable when annotated data is scarce or unavailable for specific domains or languages.
Implementation: Basic WSD System
1. Creating the Class and Sense Inventory
We create a BasicWSD class which stores a sense inventory for target words. Each word has multiple meanings and each sense is associated with keywords that help identify it.
self.sense_inventory: Stores each ambiguous word along with its senses and their associated keywords.
self.stop_words: Stores common words (e.g., the and, of) to be ignored during processing.
2. Preprocessing the Input Sentence
We define a method to clean up the input sentence. It removes unnecessary words and punctuation so that only meaningful context remains.
sentence.lower(): Converts all characters to lowercase for consistency.
Context dependency: Requires sufficient contextual clues for accurate disambiguation
Broader WSD Challenges
Data sparsity : As many word-sense combinations appear infrequently in training corpora, making supervised learning difficult for rare senses.
Sense granularity : Different lexical resources may define sense boundaries differently. Fine-grained sense distinctions are typically more difficult to disambiguate than coarse-grained categories.
Domain adaptation : Models trained on general text often perform poorly when applied to specialized domains such as medical, legal or technical texts.
Applications and Future Directions
WSD technology finds practical application across numerous domains:
Machine Translation: Accurate sense identification improves translation quality by selecting appropriate target language equivalents for ambiguous source words.
Information Retrieval: Search engines employ WSD to better understand user query intent and retrieve more relevant documents.
Content Analysis: Text processing systems benefit from precise word meanings for tasks such as sentiment analysis, topic modeling and document classification.

{kind=link}
{kind=link}