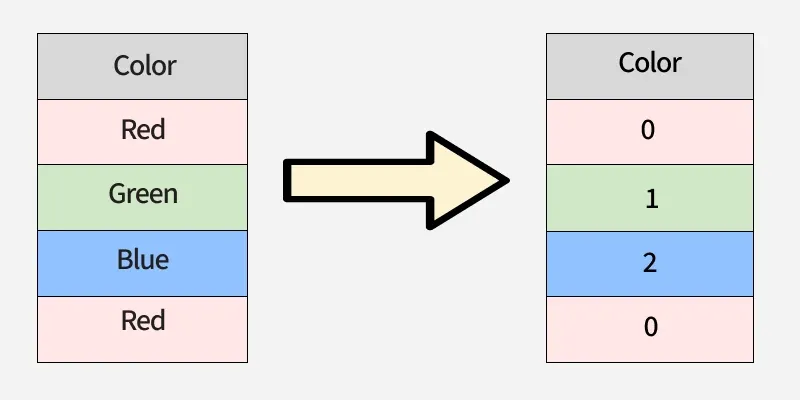
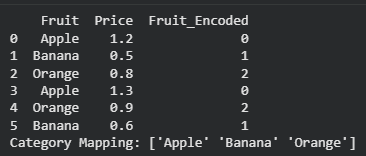
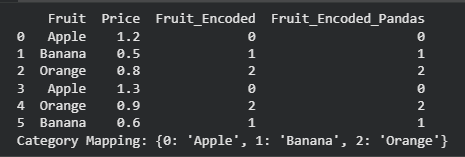
Label Encoding is a data preprocessing technique used to convert categorical values into numerical labels. It assigns a unique integer to each category, allowing machine learning algorithms to process categorical data in a numerical format. The encoded labels are typically assigned based on the sorted order of unique categories.
Produces a compact representation of categorical data using a single feature column.
Commonly applied to target variables and ordinal features in machine learning tasks.
Label Encoding is important because many ML algorithms cannot process string values (Categorical Data) directly. Hence, converting them into numerical values is essential for model training. Categorical data is broadly divided into two types:
Nominal Data: Categories without a natural order, such as colors (Red, Blue, Green).
Ordinal Data: Categories with a natural order, such as satisfaction levels (Low, Medium, High).
Label encoding works best for ordinal data, where the assigned numbers reflect the order. But when you apply it to nominal data, the numbers accidentally create a fake ranking (e.g., Red = 0, Blue = 1, Green = 2).
Linear regression treats these numbers as if “Green > Blue > Red” and assumes equal gaps between them.
This adds artificial relationships that don't exist and can mislead the model, producing wrong coefficients and predictions.
Thus, the choice of encoding must align with the data type and the algorithm used.
LabelEncoder in Scikit-Learn
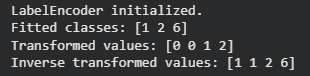
LabelEncoder is a utility in sklearn.preprocessing that converts categorical labels into numerical values. It assigns a unique integer to each class and stores the mapping for transforming and recovering original labels. The classes_ attribute contains all unique class labels discovered during fitting.
Common Methods
fit(y): Learns unique class labels from the data.
fit_transform(y): Learns labels and returns encoded values.
transform(y): Converts labels into integer values.
inverse_transform(y): Converts encoded values back to original labels.
Encoding Ordinal Features: Converts ordered categories such as Low, Medium, and High into numerical values.
Preparing Target Variables: Transforms class labels into numeric form for classification models.
Tree-Based Machine Learning Models: Provides compact categorical representations for algorithms such as Decision Trees and Random Forests.
High-Cardinality Categorical Data: Reduces dimensionality when features contain many unique categories.
Machine Learning Pipelines: Maintains consistent category-to-label mappings during training, validation, and deployment.
Advantages
Converts categorical values into numerical form quickly and efficiently.
Does not create additional columns like One-Hot Encoding, making it memory efficient for large datasets.
Preserves the natural ordering of categories, making it suitable for ordinal features.
Works effectively with tree-based models such as Decision Trees, Random Forests, XGBoost, and LightGBM, which do not misinterpret encoded integers as magnitude.
Provides a consistent category-to-label mapping that can be reused during model prediction and deployment.
Limitations
Encoded values may incorrectly imply an order among nominal categories where no natural ordering exists.
Models such as Linear Regression, Logistic Regression, KNN, and SVM may interpret encoded integers as meaningful distances, potentially reducing prediction accuracy.
Cannot directly handle unseen categories in test data, which may result in errors or incorrect mappings.
May not represent relationships effectively when dealing with features that contain a very large number of unique categories.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}