 |
VOOZH | about |
|
VOOZH | about |
This article provides a comprehensive guide to performing Exploratory Data Analysis (EDA) using Python focusing on the use ofNumPyandPandas for data manipulation and analysis.
To perform EDA in Python we need to import several libraries that provide useful tools for data manipulation and statistical analysis.
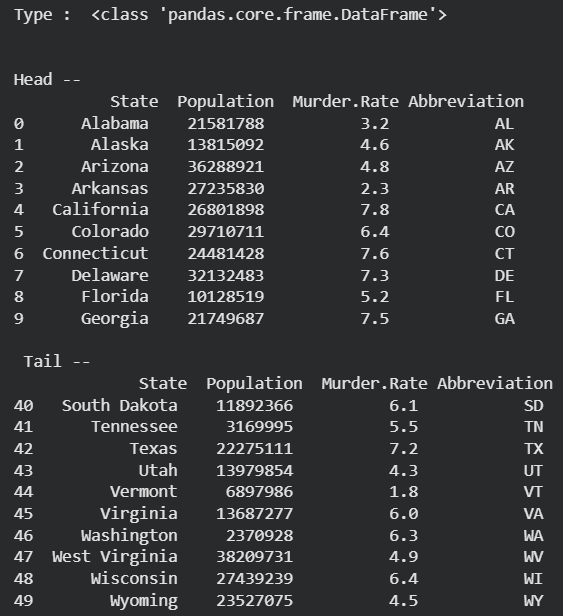
In this step we load a dataset using Pandas and explore its structure. We can check the type of data and print the first and last 10 records to get a idea of the dataset.
You can download dataset from here.
Output:
Derived columns are new columns created from existing ones. For example here we are converting the population into millions to make it more readable.
Output:
Sometimes, we may need to rename columns when column names contain special characters or spaces which cause issues in data manipulation. To do this we use .rename() function.
Output:
['State', 'Population', 'MurderRate', 'Abbreviation', 'PopulationInMillions']
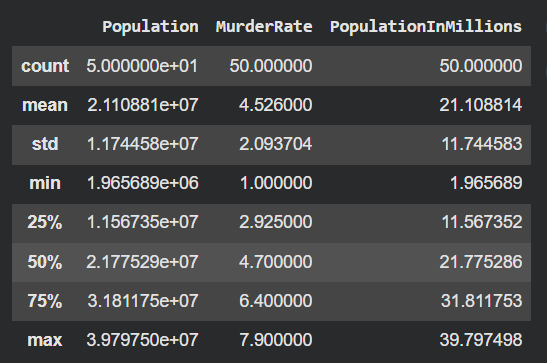
Using describe() provides a summary of the dataset which includes count, mean, standard deviation and more for each numerical column.
Output:
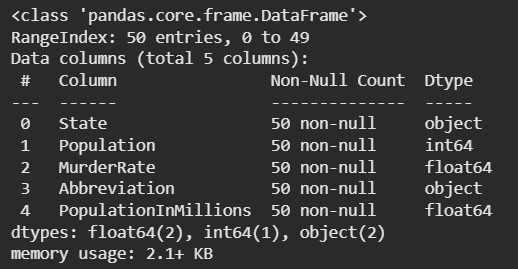
The info() method in pandas provides a summary of the dataset includes number of rows , column names, data types of each column and the memory usage of the entire dataframe. It helps to quickly understand the structure and size of the dataset.
Output:
Understanding the central tendencies of our data helps us summarize it effectively. In this step we will calculate different central tendency measures such as the mean, trimmed mean, weighted mean and median for the dataset's numerical columns.
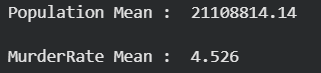
The mean is the average value of a dataset. It's calculated by summing all values and dividing by the number of values. In pandas it can be with help of mean() function.
Output:
Trimmed mean calculates the average by removing a certain percentage of the highest and lowest values in the dataset. This helps reduce the impact of outliers or extreme values that could skew the overall mean.
Output:
A weighted mean assigns different weights to different data points. Here we calculate the murder rate weighted by the population meaning larger states have more influence on the mean.
Output:
Weighted MurderRate Mean: 4.716864961131351
The median is the middle value when the data is sorted and it is useful for understanding the central tendency especially when the data has outliers.
Output:
Here we have learn how to use Pandas to perform various EDA tasks such as loading data, inspecting data types, adding and modifying columns and calculating key statistics like mean, median and trimmed mean.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}