 |
VOOZH | about |
|
VOOZH | about |
Working on Big Data has become very common today, So we require some libraries which can facilitate us to work on big data from our systems (i.e., desktops, laptops) with instantaneous execution of Code and low memory usage.
Vaex is a Python library which helps us achieve that and makes working with large datasets super easy. It is especially for lazy Out-of-Core DataFrames (similar to Pandas). It can visualize, explore, perform computations on big tabular datasets swiftly and with minimal memory usage.
Using Conda:
conda install -c conda-forge vaex
Using pip:
pip install --upgrade vaex
Vaex helps us work with large datasets efficiently and swiftly by lazy computations, virtual columns, memory-mapping, zero memory copy policy, efficient data cleansing, etc. Vaex has efficient algorithms and it emphasizes aggregate data properties instead of looking at individual samples. It is able to overcome several shortcomings of other libraries (like:- pandas). So, Let's Explore Vaex:-
For large tabular data, the reading performance of Vaex is much faster than pandas. Let's analyze by importing same size dataset with both libraries. Link to the dataset
Reading Performance of Pandas:
Output:
Wall time: 1min 8s
Reading Performance of Vaex: (We read dataset in Vaex using vaex.open)
Output:
Wall time: 1.34 s
Vaex took very little time to read the same size dataset as compared to pandas:
Output:
Size = 12852000, 36 12852000, 36
Vaex uses a lazy computation technique (i.e., compute on the fly without wasting RAM). In this technique, Vaex does not do the complete calculations, instead, it creates a Vaex expression, and when printed out it shows some preview values. So Vaex performs calculations only when needed else it stores the expression. This makes the computation speed of Vaex exceptionally fast. Let's Perform an example on a simple computation:
Pandas DataFrame:
Output:
👁 Image
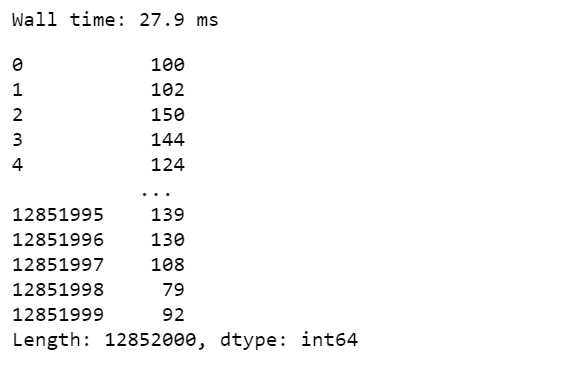
Vaex DataFrame:
Output:
👁 ImageVaex can calculate statistics such as mean, sum, count, standard deviation, etc., on an N-dimensional grid up to a billion (109) objects/rows per second. So, Let's Compare the performance of pandas and Vaex while computing statistics:-
Pandas Dataframe:
Output:
Wall time: 741 ms 49.49811570183629
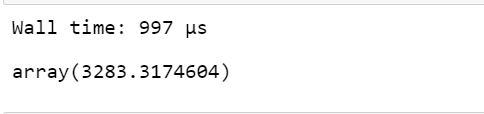
Vaex DataFrame:
Output:
Wall time: 347 ms array(49.4981157)
Unlike Pandas, No copies of memory are created in Vaex during data filtering, selections, subsets, cleansing. Let's take the case of data filtering, in achieving this task Vaex uses very little memory as no memory copying is done in Vaex. and the time for execution is also minimal.
Pandas:
Output:
Wall time: 24.1 s
Vaex:
Output:
Wall time: 91.4 ms
Here data filtering results in a reference to the existing data with a boolean mask which keeps track of selected rows and non-selected rows. Vaex performs multiple computations in single pass over the data:-
Output:
Wall time: 128 ms array([ 9.4940431, 59.49137605])
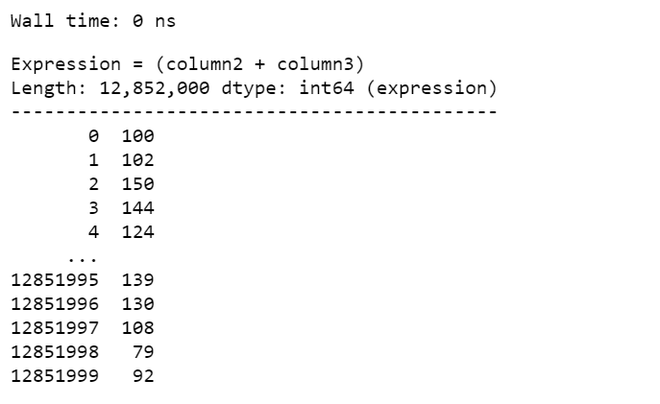
When we create a new column by adding expression to a DataFrame, Virtual columns are created. These columns are just like regular columns but occupy no memory and just stores the expression that defines them. This makes the task very fast and reduces the wastage of RAM. And Vaex makes no distinction between regular or virtual columns.
Output:
👁 ImageVaex provides a faster alternative to pandas's groupby as 'binby' which can calculate statistics on a regular N-dimensional grid swiftly in regular bins.
Output:
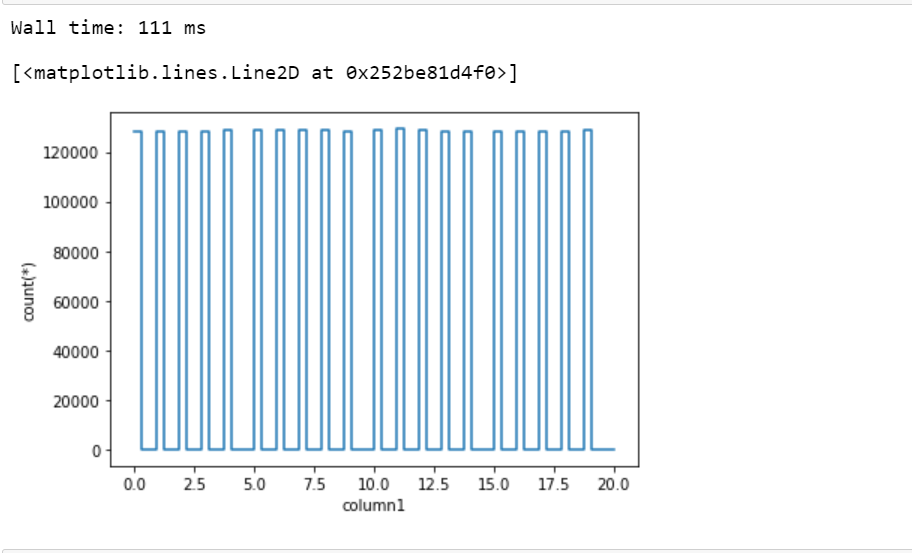
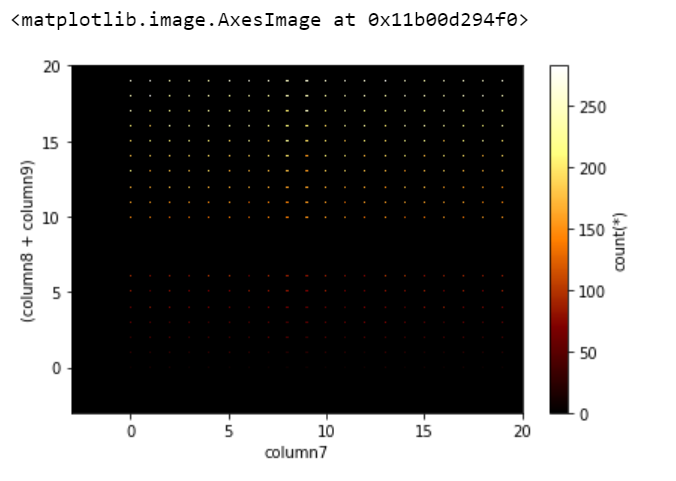
👁 ImageVisualization of the large dataset is a tedious task. But Vaex can compute these visualizations pretty quickly. The dataset gives a better idea of data distribution when computed in bins and Vaex excels in group aggregate properties, selections, and bins. So, Vaex is able to visualize swiftly and interactively. By Vaex, visualizations can be done even in 3-dimensions on large datasets.
Let's plot a simple 1-dimensional graph:
Output:
👁 ImageOutput:
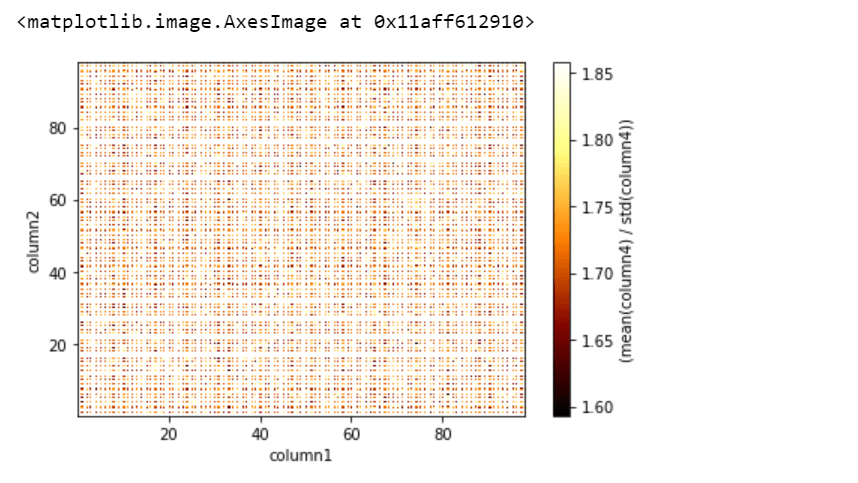
👁 ImageWe can add statistics expression and visualize by passing the "what=<statistic>(<expression>)" argument. So let's perform a slightly complicated visualization:
Output:
👁 ImageHere, the 'vaex.stat.<statistic>' objects are very similar to Vaex expressions, which represent an underlying calculation, and also we can apply typical arithmetic and Numpy functions to these calculations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}