 |
VOOZH | about |
|
VOOZH | about |
Prerequisites: Pandas
Pandas can be employed to count the frequency of each value in the data frame separately. Let's see how to Groupby values count on the pandas dataframe. To count Groupby values in the pandas dataframe we are going to use groupby() size() and unstack() method.
Syntax:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
Parameters :
- by : mapping, function, str, or iterable
- axis : int, default 0
- level : If the axis is a MultiIndex (hierarchical), group by a particular level or levels
- as_index : For aggregated output, return object with group labels as the index. Only relevant for DataFrame input. as_index=False is effectively “SQL-style” grouped output
- sort : Sort group keys. Get better performance by turning this off. Note this does not influence the order of observations within each group. groupby preserves the order of rows within each group.
- group_keys : When calling apply, add group keys to index to identify pieces
- squeeze : Reduce the dimensionality of the return type if possible, otherwise return a consistent type
Returns : GroupBy object
Syntax:
Dataframe.size()
Syntax:
Dataframe.unstack()
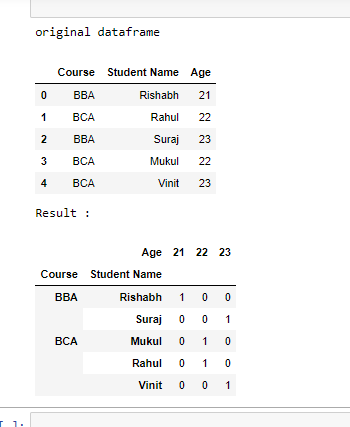
Example1:
Output:
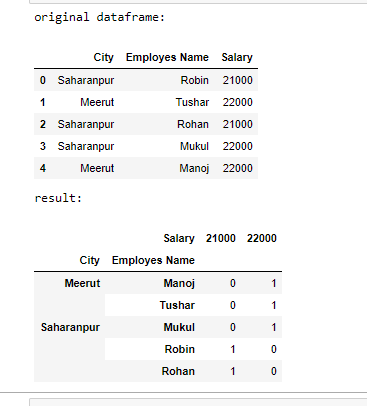
Example 2:
Output:
{kind=link}
{kind=link}
{kind=link}