 |
VOOZH | about |
|
VOOZH | about |
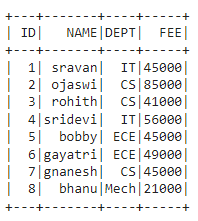
In this article, we will discuss how to perform aggregation on multiple columns in Pyspark using Python. We can do this by using Groupby() function
Output:
👁 ImageIn PySpark, groupBy() is used to collect the identical data into groups on the PySpark DataFrame and perform aggregate functions on the grouped data
dataframe.groupBy('column_name_group').count()
dataframe.groupBy('column_name_group').mean('column_name')
dataframe.groupBy('column_name_group').max('column_name')
dataframe.groupBy('column_name_group').min('column_name')
dataframe.groupBy('column_name_group').sum('column_name')
dataframe.groupBy('column_name_group').avg('column_name').show()
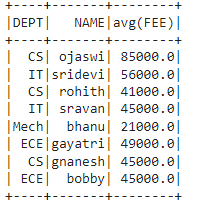
We can groupBy and aggregate on multiple columns at a time by using the following syntax:
dataframe.groupBy('column_name_group1','column_name_group2',............,'column_name_group n').aggregate_operation('column_name')
Output:
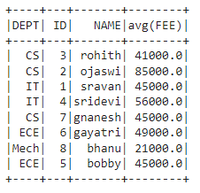
👁 ImageExample 2: Aggregation on all columns
{kind=link}
{kind=link}
{kind=link}
{kind=link}