 |
VOOZH | about |
|
VOOZH | about |
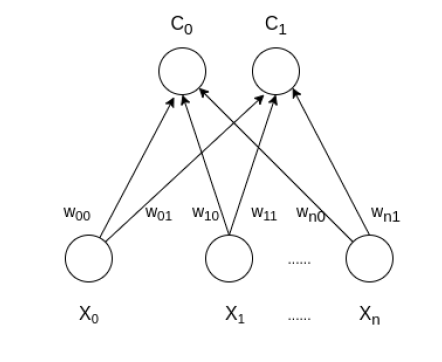
A Self Organizing Map (SOM) or Kohonen Map is an unsupervised neural network algorithm based on biological neural models from the 1970s. It uses a competitive learning approach and is primarily designed for clustering and dimensionality reduction. SOM effectively maps high-dimensional data to a lower-dimensional grid enabling easier interpretation and visualization of complex datasets.
It consists of two primary layers:
Here are the step by step explanation of its working:
The weights of the output neurons are randomly initialized. These weights represent the features of each neuron and will be adjusted during training.
For each input vector, SOM computes the Euclidean distance between the input and the weight vectors of all neurons. The neuron with the smallest distance is the winning neuron.
Formula :
where
The winning neuron’s weights are updated to move closer to the input vector. The weights of neighboring neurons are also adjusted but with smaller changes.
Formula:
where
The learning rate α\alphaα decreases over time allowing the map to converge to stable values.
Formula:
The training stops when the maximum number of epochs is reached or when the weights converge.
Now let’s walk through a Python implementation of the SOM algorithm. The code is divided into blocks for clarity.
We will use the math library to compute the Euclidean distance between the input vector and the weight vector.
In this class, we define two important functions, winner() to compute the winning neuron by calculating the Euclidean distance between the input and weight vectors of each cluster and update() to update the weight vectors of the winning neuron according to the weight update rule.
In this section, we define the training data and initialize the weights. We also specify the number of epochs and the learning rate.
Here, we loop through each training example for the specified number of epochs, compute the winning cluster and update the weights. For each epoch and training sample we:
After training the SOM network, we use a test sample s and classify it into one of the clusters by computing which cluster has the closest weight vector to the input sample. Finally, we print the cluster assignment and the trained weights for each cluster.
The following block runs the main() function when the script is executed.
Output:
The output will display which cluster the test sample belongs to and the final trained weights of the clusters.
Test Sample s belongs to Cluster: 0
Trained weights: [[0.6000000000000001, 0.8, 0.5, 0.9], [0.3333984375, 0.0666015625, 0.7, 0.3]]
{kind=link}
{kind=link}