 |
VOOZH | about |
|
VOOZH | about |
In this article, we will explore how to use SQLAlchemy Group By With Full Child Objects in Python. SQLAlchemy provides several techniques to achieve SQLAlchemy Group By with Full Child Objects.
In this section, we are making a connection with the database, we are creating the structure of two tables with parent-child relationships. Also, we are inserting data in both tables.
Output
Joinedload technique in SQLAlchemy is used to explicitly instruct the ORM to perform a join query to load related objects along with the primary object. In SQLAlchemy, you can enable joined-load loading using the options() and joinedload() methods.
session.query(Department,func.count(Employee.emp_id).label("employee_count"))\
.join(Department.employees)\
.group_by(Department)\
.options(joinedload(Department.employees))\
.all()
.join(Department.employees)
.group_by(Department)
.options(joinedload(Department.employees)).all()Code Implementation
Output
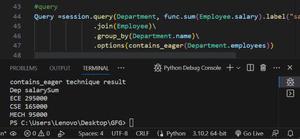
contains eager technique in SQLAlchemy is used to indicate that a query should eagerly load a specific relationship and include it in the result set. It is particularly useful when you have loaded a relationship using a separate query or a different loading technique, and you want to include those related objects in the result set of the current query.
query = session.query(Department, func.sum(Employee.salary)) \
.join(Employee) \
.group_by(Department.name) \
.options(contains_eager(Department.employees)) \
.all()
.join(Employee)
.group_by(Department.name)
.options(contains_eager(Department.employees))
.all()Code Implemention
Output
We first define a subquery that calculates the count of employees per department. The subquery is created using session.query() with the necessary columns and aggregations, followed by a join() with the Employee table and a group_by() on the Department.id column. The subquery() at the end converts the query into a subquery object.
session.query(Department.id, func.count(Employee.emp_id).label('employee_count'))
.join(Employee)
.group_by(Department.id)
.subquery()
.join(Employee)
.group_by(Department.id)
.subquery()
Code
Output :
By using the Load technique, you can fine-tune how SQLAlchemy fetches related objects, optimizing performance and reducing the number of queries issued to the database.
query = session.query(Department.name, func.avg(Employee.salary))
.join(Employee, Employee.dep_id == Department.id)
.group_by(Department.name)
.options(Load(Employee))
.all()
name attribute from the Department model and calculates the average salary using the func.avg() function on the salary attribute from the Employee model.): We group the results by the name attribute of the Department model. This ensures that we get the average salary per department.() technique. By passing Load(Employee), we indicate that we want to customize the loading behavior for the Employee objects in the query.Code
Output
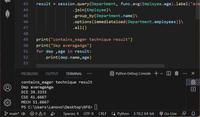
Load technique result
Dep averageSalary
ECE 98333.3333
CSE 55000.0000
MECH 31666.6667
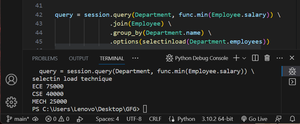
The selectinload() method allows you to load related objects in a separateSELECTstatement rather than joining them with the main query. This can be useful when you have a large number of related objects or when the relationship involves many-to-many or one-to-many associations.
Output
Immediate load is a technique in SQLAlchemy that loads related objects immediately along with the parent object when the query is executed. It allows you to retrieve all the necessary data in a single query, reducing the number of database round-trips. It can be achieved by using the immediateload() in options().
Output
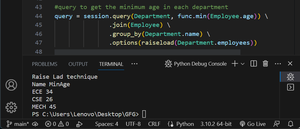
The raiseload() method is used to specify that a particular relationship should be loaded using a separate SQL query when accessed.
Output
The noload technique is used to specify that a particular relationship should not be loaded at all. It is useful when you want to exclude a specific relationship from being loaded in a query, even if it has a default loading strategy.
Output
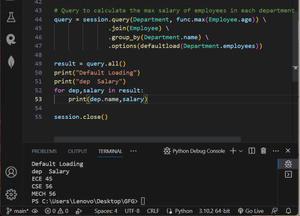
Dep maxSalary
ECE 120000
CSE 75000
MECH 40000
We can simply achieve the same functionality by using lazy loading with the help of foreign key relations no need for joins and group_by clauses.
Output
The defaultload technique in SQLAlchemy is used to control the loading behavior of relationships when querying objects from the database. By default, SQLAlchemy loads all related objects for a given relationship when the parent object is queried. However, in some cases, loading all related objects upfront can lead to unnecessary performance overhead.
Output
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}