 |
VOOZH | about |
|
VOOZH | about |
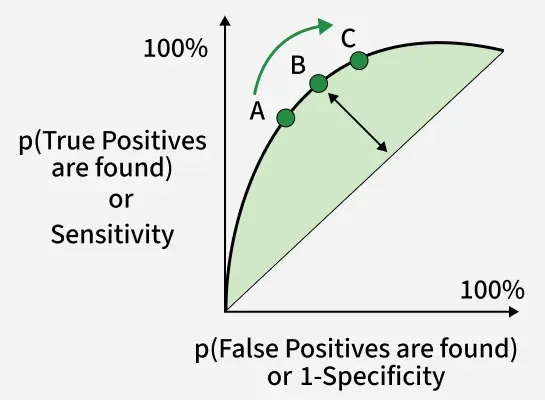
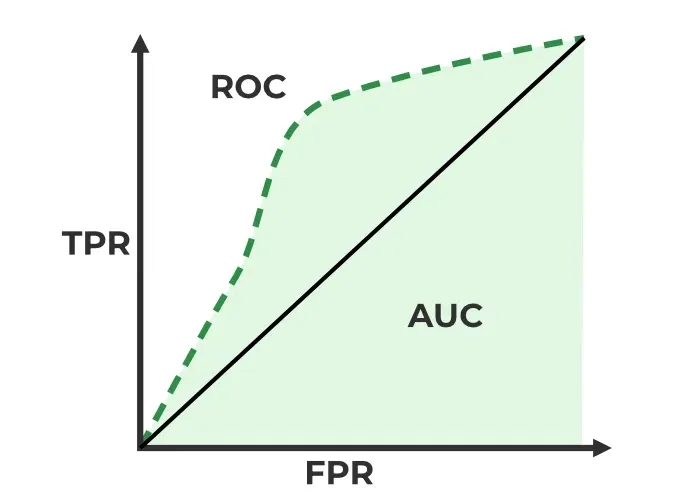
AUC-ROC curve is a graph used to check how well a binary classification model works. It helps us to understand how well the model separates the positive cases like people with a disease from the negative cases like people without the disease at different threshold level. It shows how good the model is at telling the difference between the two classes by plotting:
A better model has a higher AUC (Area Under the Curve), which indicates a stronger ability to distinguish between classes.
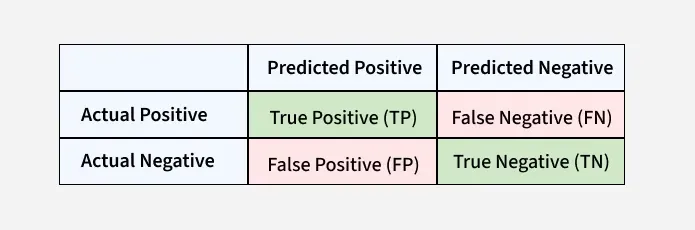
These terms are derived from the confusion matrix which provides the following values:
AUC-ROC curve helps us understand how well a classification model distinguishes between the two classes. Imagine we have 6 data points and out of these:
Now the model will give each data point a predicted probability of belonging to Class 1. The AUC measures the model's ability to assign higher predicted probabilities to the positive class than to the negative class. Here’s how it work:
AUC-ROC is effective when:
In cases of highly imbalanced datasets AUC-ROC might give overly optimistic results. In such cases the Precision-Recall Curve is more suitable focusing on the positive class.
Model Performance with AUC-ROC:
In short AUC gives you an overall idea of how well your model is doing at sorting positives and negatives, without being affected by the threshold you set for classification. A higher AUC means your model is doing good.
We will be importing numpy, pandas, matplotlib and scikit learn.
Using an 80-20 split ratio, the algorithm creates artificial binary classification data with 20 features, divides it into training and testing sets and assigns a random seed to ensure reproducibility.
To train the Random Forest and Logistic Regression models we use a fixed random seed to get the same results every time we run the code. First we train a logistic regression model using the training data. Then use the same training data and random seed we train a Random Forest model with 100 trees.
Using the test data and a trained Logistic Regression model the code predicts the positive class's probability. In a similar manner, using the test data, it uses the trained Random Forest model to produce projected probabilities for the positive class.
Using the test data the code creates a DataFrame called test_df with columns labeled "True," "Logistic" and "RandomForest," add true labels and predicted probabilities from Random Forest and Logistic Regression models.
Plot the ROC curve and compute the AUC for both Logistic Regression and Random Forest. The ROC curve compares models based on True Positive Rate vs False Positive Rate, while the red dashed line shows random guessing.
Output:
The plot computes the AUC and ROC curve for each model i.e Random Forest and Logistic Regression, then plots the ROC curve. The ROC curve for random guessing is also represented by a red dashed line and labels, a title and a legend are set for visualization.
For multiclass classification, AUC-ROC is extended using the One-vs-All (OvA) approach. Each class is treated as the positive class once, and the remaining classes are grouped as the negative class. For example, if you have classes A, B, C, D, you will get four ROC curves one for each class:
1. One-vs-All Conversion: Treat each class as the positive class and all others combined as the negative class.
2. Train a Binary Classifier per Class: Fit the model separately for each class-vs-rest combination.
3. Compute AUC-ROC for Each Class:
4. Compare Performance: A higher AUC score means the model is better at distinguishing that class from the others.
The program creates artificial multiclass data, divides it into training and testing sets and then uses the One-vs-Restclassifier technique to train classifiers for both Random Forest and Logistic Regression. It plots the two models multiclass ROC curves to demonstrate how well they discriminate between various classes.
Three classes and twenty features make up the synthetic multiclass data produced by the code. After label binarization, the data is divided into training and testing sets in an 80-20 ratio.
The program trains two multiclass models i.e a Random Forest model with 100 estimators and a Logistic Regression model with the One-vs-Rest approach. With the training set of data both models are fitted.
The ROC curves and AUC scores for each class are computed and plotted for both models. A dashed line indicates random guessing, helping visualize how well each model separates multiple classes.
Output:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}