 |
VOOZH | about |
|
VOOZH | about |
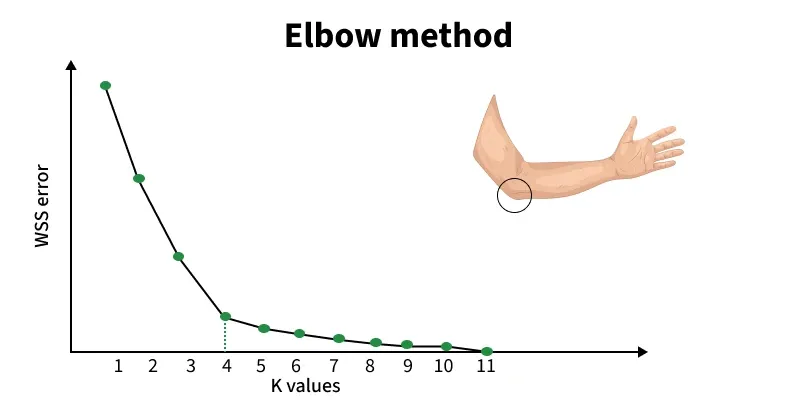
The Elbow Method is used to find the optimal number of clusters (k) in K-Means by analyzing how the clustering performance changes with different k values.
The Elbow Method works in the following steps:
1. We begin by selecting a range of k values (for example, 1 to 10).
2. For each k, we run K-Means and calculate WCSS (Within-Cluster Sum of Squares), which shows how close the data points are to their cluster centroids:
Where represents the distance between the data point in cluster i and the centroid of that cluster.
3. After computing WCSS for all k values, we plot k vs WCSS.
4. WCSS always decreases as k increases because more clusters reduce the internal spread.
5. However, after a certain point, the improvement becomes very small. This bend or “elbow” in the curve indicates the point where adding more clusters no longer gives meaningful improvement.
The goal is to identify the point where the rate of decrease in WCSS sharply changes, indicating that adding more clusters (beyond this point) yields diminishing returns. This "elbow" point suggests the optimal number of clusters.
Two metrics commonly used in the Elbow Method are Distortion and Inertia.
Distortion measures the average squared distance between each data point and its assigned cluster center. It's a measure of how well the clusters represent the data. A lower distortion value indicates better clustering.
where,
Inertia is the sum of squared distances of each data point to its closest cluster center. It's essentially the total squared error of the clustering. Like distortion, a lower inertia value suggests better clustering.
In the Elbow Method, we compute distortion or inertia for different k values and plot them. The point where the decrease begins to slow the “elbow” usually indicates the optimal number of clusters.
Let's implement the Elbow method,
We will import numpy, matplotlib, scikit learn and scipy for this.
We will create a random array and visualize its distribution
Output:
From the above visualization, we can see that the optimal number of clusters should be around 3. But visualizing the data alone cannot always give the right answer. Hence we demonstrate the following steps.
In this step, we will fit the K-means model for different values of k (number of clusters) and calculate both the distortion and inertia for each value.
a) Displaying Distortion Values
Output:
Distortion values:
1 : 14.90249433106576
2 : 5.146258503401359
3 : 1.8817838246409675
4 : 0.856122448979592
5 : 0.7166666666666667
6 : 0.5484126984126984
7 : 0.4325396825396825
8 : 0.3817460317460318
9 : 0.3341269841269841
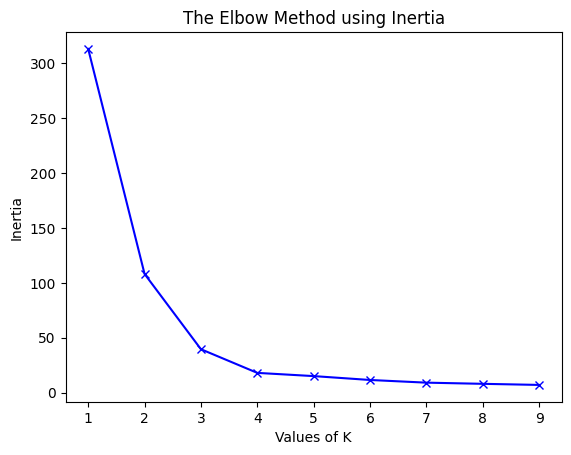
b) Displaying Inertia Values:
Output:
Inertia values:
1 : 312.95238095238096
2 : 108.07142857142854
3 : 39.51746031746032
4 : 17.978571428571428
5 : 15.049999999999997
6 : 11.516666666666666
7 : 9.083333333333334
8 : 8.016666666666667
9 : 7.0166666666666675
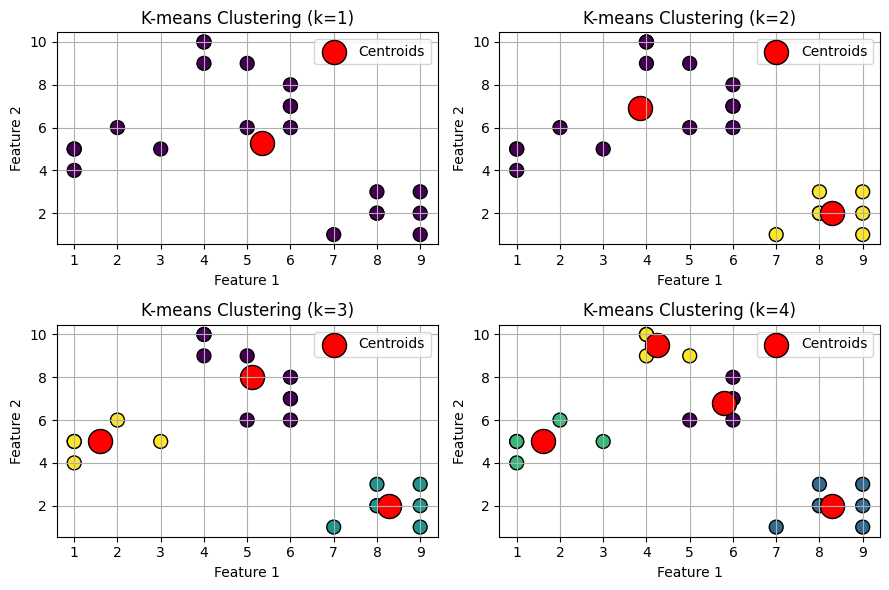
We will plot images of data points clustered for different values of k. For this, we will apply the k-means algorithm on the dataset by iterating on a range of k values.
Output:
You can download the source code from here: Source Code
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}
{kind=link}
{kind=link}
{kind=link}