 |
VOOZH | about |
|
VOOZH | about |
The Fisher Score is a simple used to select important features for classification tasks. It works by comparing how much a feature varies between different classes versus how much it varies within the same class. Features that show big differences between classes, but are consistent within each class, are considered useful for classification.
For a given feature and a dataset with classes, the Fisher Score is defined as:
Where:
A feature gets a high Fisher Score if the classes are clearly separated by it and it is consistent within each class.
Suppose you are building a spam email classifier using a bag-of-words model. Each email is converted into a vector where each feature represents the frequency of a specific word (e.g., “offer”, “free”, “meeting”, etc.).
Now, you want to select the most informative words that help differentiate between the two classes: spam and not spam.
Fisher Score promotes features with high between-class variance (different means across classes) and low within-class variance (consistency within each class), which is ideal for discriminating features.
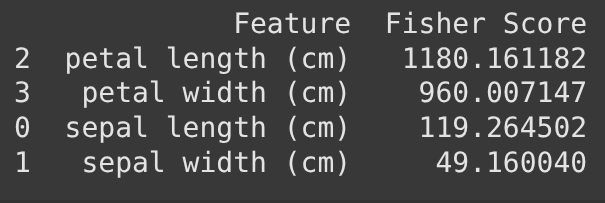
Here’s a basic example using sklearn to compute Fisher scores with the SelectKBest method and f_classif (which computes ANOVA F-statistics, equivalent to Fisher scores):
Output:
Feature Selection Method | Type | Dependency on Class Labels | Computational Cost | Interpretability |
|---|---|---|---|---|
Fisher Score | Filter | Yes | Low | High |
Mutual Information | Filter | Yes | Moderate | Medium |
Recursive Feature Elim | Wrapper | Yes | High | Medium |
PCA | Unsupervised | No | Moderate | Low |
{kind=link}
{kind=link}