The KNN Imputer is a machine learning–based method for filling missing values in datasets. Instead of using a single statistic (like mean or median), it estimates missing values using the values of the k most similar data points (neighbors).
Multivariate approach: Considers multiple features simultaneously.
Data-driven: Uses patterns in the dataset, not external assumptions.
Robust: Better preserves relationships between variables compared to univariate methods.
Working of K-Nearest Neighbors Imputer
The method is built on the K-Nearest Neighbors (KNN) algorithm, commonly used for classification and regression. The steps are:
Distance Calculation: Compute distances between the data point with missing values and all others. By default, a NaN-aware Euclidean distance is used.
Identify Neighbors: Select the k closest neighbors based on computed distances.
Imputation: Replace the missing value with the average (for continuous data) or majority vote (for categorical data) of the neighbors’ values.
Multivariate Handling: Takes all available features into account for improved accuracy.
Example: Imputing Missing Values with KNN Imputer
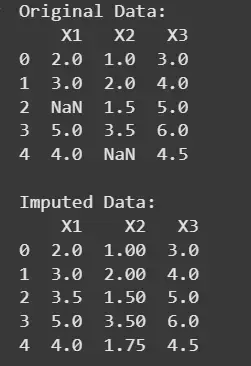
Suppose we have the following dataset,
Observation
X1
X2
X3
1
2.0
1.0
3.0
2
3.0
2.0
4.0
3
NaN
1.5
5.0
4
5.0
3.5
6.0
5
4.0
NaN
4.5
We will impute the missing values.
Step 1: Identify the Missing Values
Missing value: in observation 3.
Step 2: Compute Distance
We compute distances between Observation 3 and other observations using features and .
Euclidean Distance Formula:
1. Distance between Observation 3 and 1:
2. Distance between Observation 3 and 2:
3. Distance between Observation 3 and 4:
Step 3: Find the Nearest Neighbors
Closest neighbor: Observation 2(1.12) and Observation 1(2.06)
Step 4: Impute the Missing Value
Take the mean of neighbors’ values in X₁:
So, the missing value in X₁ (Observation 3) is imputed as 2.5.
Code Example
Let's see the implementation of using KNN Imputer.

{kind=link}
{kind=link}