Gradient Descent is an optimization algorithm used to find the local minimum of a function. It is used in machine learning to minimize a cost or loss function by iteratively updating parameters in the opposite direction of the gradient. It works by calculating the derivative i.e slope of a function and moving in the direction opposite to the slope to reach a minimum. It can be applied to any differentiable function.
👁 GD-IM3 Gradient Descent Mathematical Concept The mathematical formula for Gradient Descent:
Where:
is the current value of the variable is the learning rate is the derivative of the function The derivative points in the direction of the steepest ascent. By moving in the opposite direction, we approach the local minimum.
Implementation Here’s an example to find the minimum of .
Step 1: Importing Libraries Importing libraries like Numpy and Matplotlib .
Step 2: Minimize Function Defining function to minimize.
Step 3: Derivative Finding derivative of the function.
Step 4: Gradient Descent Implementing Gradient Descent.
Output:
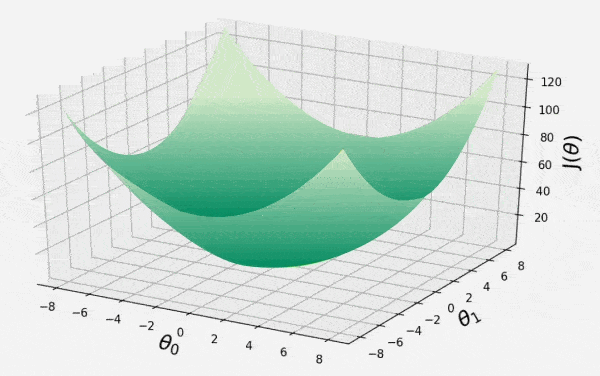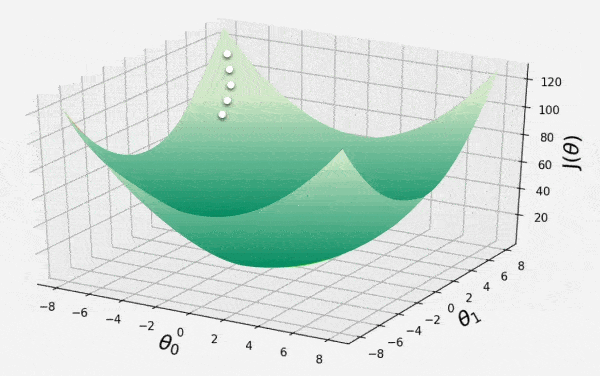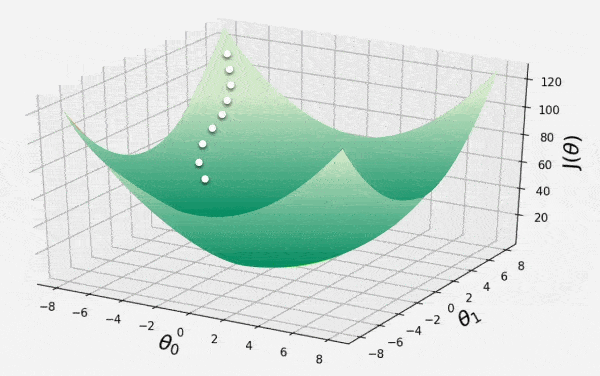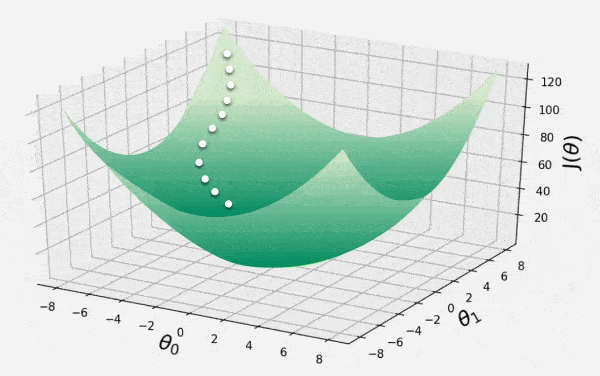
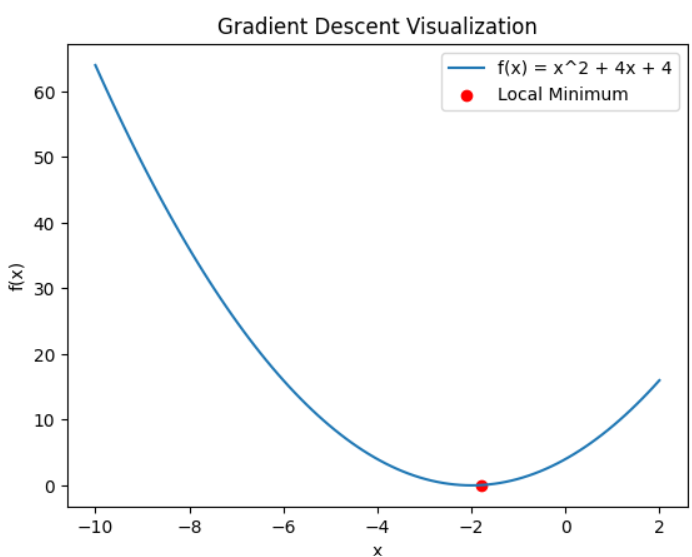
👁 GD-IM1 Local Minimum Step 5: Visualizing Visualizing using Matplotlib.
Output:
👁 GD-IM2 Graph Here the red dot shows the local minimum reached by gradient descent.
Applications Machine Learning: Optimizes linear and logistic regression models by minimizing cost functions helping models learn optimal parameters. Deep Learning: Trains neural networks by adjusting weights and biases to minimize loss enabling models to learn complex patterns. Economics and Finance: Used for optimization tasks like minimizing costs, maximizing profits or portfolio optimization. Physics and Engineering: Solves systems where minima represent stable states such as energy optimization or mechanical design. Computer Vision: Optimizes models for tasks like image recognition and object detection improving performance in classification and segmentation. Advantages Simple to Implement: Easy to code and understand, suitable for beginners and professionals. Flexible: Works for functions with one or multiple variables across many optimization problems. Widely Used: Core method in machine learning and deep learning for training models. Efficient for Large Problems: Mini-batch or stochastic versions handle large datasets effectively while saving computation time. Iterative Improvement: Gradually improves parameters giving control over convergence and model refinement. Limitations May Converge to Local Minimum: In non-convex functions, it can get trapped in a local minimum or saddle point instead of reaching the global minimum. Sensitive to Learning Rate: A high learning rate may overshoot the minimum, while a low one makes convergence very slow. Can Be Slow for Large Datasets: Processing the entire dataset before each update as in batch gradient descent, can be computationally expensive. Requires Differentiable Functions: Since it relies on derivatives, gradient descent cannot be directly applied to non-differentiable functions. 
{kind=link}
{kind=link}
{kind=link}
{kind=link}