 |
VOOZH | about |
|
VOOZH | about |
Parallelizing K-Nearest Neighbors (KNN) computations can significantly reduce the time needed for processing, especially when dealing with large datasets. The KNN algorithm, which involves computing distances between test samples and all training samples, is computationally expensive and benefits substantially from parallelization. By distributing the workload across multiple processors, GPUs, or machines, we can achieve faster and more efficient KNN computations.
The K-Nearest Neighbors algorithm is well-suited for parallelization since each test sample’s distance calculation is independent of others. This independence allows for splitting the computations among different processors or machines, each handling separate test points or training points concurrently. Methods for parallelizing KNN computations include: multi-core processing, GPU acceleration, and distributed computing frameworks.
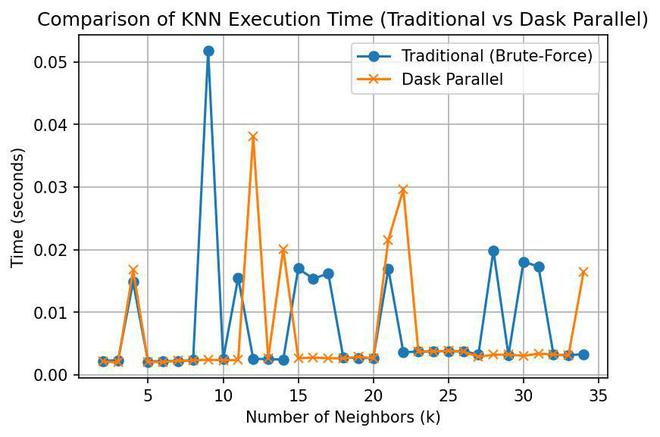
👁 ImageBy comparing execution times with and without parallel processing, the efficiency gain becomes clear, especially as dataset size grows. While parallelization brings notable speed-ups for large datasets, the advantages are less pronounced with smaller datasets, where the overhead of managing parallel tasks can outweigh the benefits.
By comparing the time taken for KNN with and without parallel processing, the graph highlights the reduced computational time when using parallelization techniques. Annotations on the plot clarify the difference, showing how using multiple CPU cores (via parallelization) can significantly improve performance for larger datasets. However, the graph also reveals that for smaller datasets, the improvement is less noticeable, and the complexity of managing parallel tasks can sometimes limit efficiency.
Implementing parallelization techniques can considerably reduce KNN's execution time, making it scalable for real-world applications involving large datasets.
Explanation:
joblib and concurrent.futures in Python make it easy to implement multi-core parallelization.CuPy and scikit-cuda leverage GPU processing to speed up distance calculations, making it particularly effective for high-dimensional and large datasets.NumPy and TensorFlow, reduce the need for loops by performing distance calculations in a single, optimized step. While not strictly parallelization, vectorization can substantially reduce computation time and is effective for handling medium to large datasets.Code Example for DASK:
Output:
Average Time Taken by Brute Force: 0.00816420352820194
Average Time Taken by Dask {prallel processing} 0.00662552226673473
Parallelizing KNN computations enhances the algorithm’s efficiency and scalability, making it more suitable for large datasets and real-time applications. Depending on the dataset size, hardware availability, and application requirements, choosing the appropriate parallelization method—whether multi-core processing, GPU acceleration, distributed computing, or vectorization—can optimize KNN performance. Balancing the complexity of parallelization with the anticipated speed gains is essential for achieving optimal results.
{kind=link}
{kind=link}