Implementing L1 and L2 regularization using Sklearn
Last Updated : 31 Mar, 2026
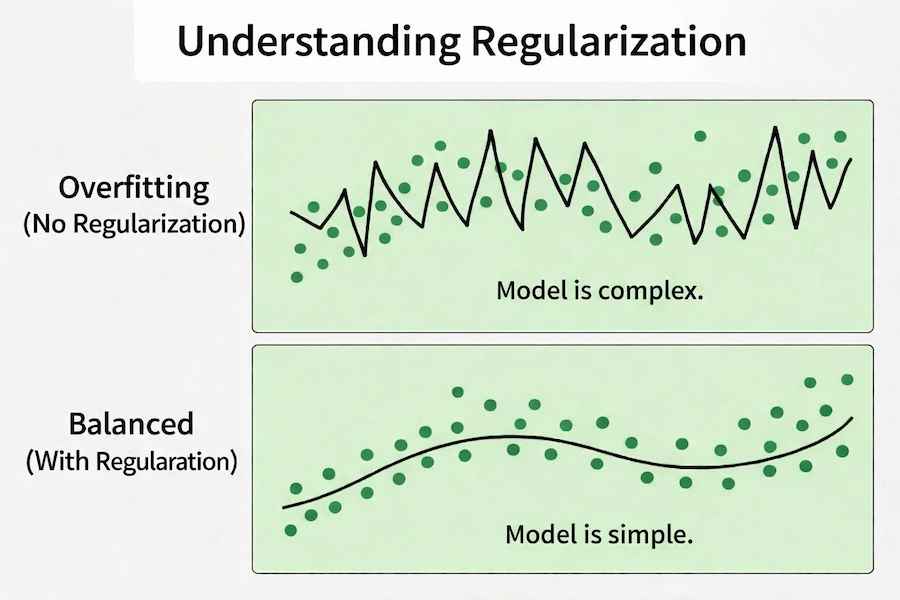
Regularization is a technique used to prevent overfitting in machine learning models. It works by adding a penalty to the loss function so the model does not become too complex. The two most common types are L1 (Lasso) and L2 (Ridge) regularization. Now let us understand the concept in a simple flow:
We first control model complexity so it does not overfit the training data.
We then apply L1 regularization, which can reduce some feature coefficients to zero.
Next, we apply L2 regularization, which reduces coefficient values but keeps all features.
Finally, we choose the appropriate method depending on whether we want feature selection (L1) or coefficient shrinkage (L2).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}